

まとめ:
- Google は、新しい Gemini 2.0 Flash ベータ版を使用したネイティブ画像生成および編集機能を開始しました。
- この機能は現在 AI Studio で無料で利用可能で、簡単なテキスト コマンドを使用して一連の調整された画像を生成および編集できます。
- 要素の削除や追加、テキストの挿入、画像の色付け、ビジュアルストーリーの作成など、さまざまな操作を行うことができます。
AI の分野で「ネイティブ マルチモーダル」という言葉が聞かれるようになってから 2.0 年以上経ちますが、企業が AI モデルのマルチモーダルな可能性を最大限に発揮するのはこれまで時間がかかりました。 Google がついに最新プロトタイプ「Gemini XNUMX Flash Experimental」をリリースしました。 オリジナル画像を生成および編集する機能おい.
さて、画像生成の重要性とは何なのかと疑問に思うかもしれません。 AI 画像生成は、ChatGPT などの主要な AI チャットボットで以前から利用可能でした。 ChatGPT や Gemini で AI 画像を生成する場合、その画像は Dall-E 3 や Imagen 3 などの特殊な拡散ベースのモデルに送られます。これらのモデルは画像でトレーニングされており、画像を生成するためだけに設計されています。これはメイン AI モデルの拡張であり、その一部ではありません。
しかし、言語視覚モデルは、 双子座 ネイティブマルチメディアなので、テキストと画像の両方を本質的に理解、生成、変更できます。今のところ、この機能をユーザーに提供しているテクノロジー企業はありません。 OpenAIは4年にGPT-2024oでネイティブ画像生成機能を実証しましたが、これもリリースされませんでした。
 オリジナル画像生成機能を使用すると、次のことが可能になります。 より良い調整 さまざまなメディアの膨大なデータセットでマルチモーダル モデルをトレーニングします。その結果、これらのモデルは概念をより深く理解し、世界についてのより幅広い知識を示すようになります。
オリジナル画像生成機能を使用すると、次のことが可能になります。 より良い調整 さまざまなメディアの膨大なデータセットでマルチモーダル モデルをトレーニングします。その結果、これらのモデルは概念をより深く理解し、世界についてのより幅広い知識を示すようになります。
画像生成に加えて、シンプルなテキストコマンドを使ってシームレスに画像を編集できます。例えば、画像をアップロードし、モデルにサングラスを追加したり、太字のテキストを挿入したり、オブジェクトを削除したりといった操作を指示できます。新しいコマンドを実行するたびに画像全体を再生成する拡散モデルとは異なり、ネイティブマルチメディアモデルは複数の編集作業間で一貫性を維持します。
Gemini 2.0 Flashデモを使用して画像を作成する
現在、オリジナル画像作成機能は一般ユーザーにはご利用いただけません。ネイティブ画像生成機能を備えたGemini 2.0 Flashデモは、GoogleのAI Studioプラットフォーム(<XNUMXxDXNUMX><XNUMXxDXNUMX><XNUMXxDXNUMX><XNUMXxBXNUMX>ييا)を無料でご利用いただけます。
このモデルは AI Studio でプレビューされた後、近い将来に Gemini でリリースされ、誰でも使用できるようになります。しかし、画像作成機能を搭載した新しいGeminiモデルを試してみたところ、非常に刺激的な体験となりました。
まず、Gemini の画像生成能力の一貫性を示すビジュアル ガイドを作成しました。私は Gemini に、オムレツの作り方のビジュアル ガイドを作成し、プロセスの各ステップの写真を作成するように依頼しました。
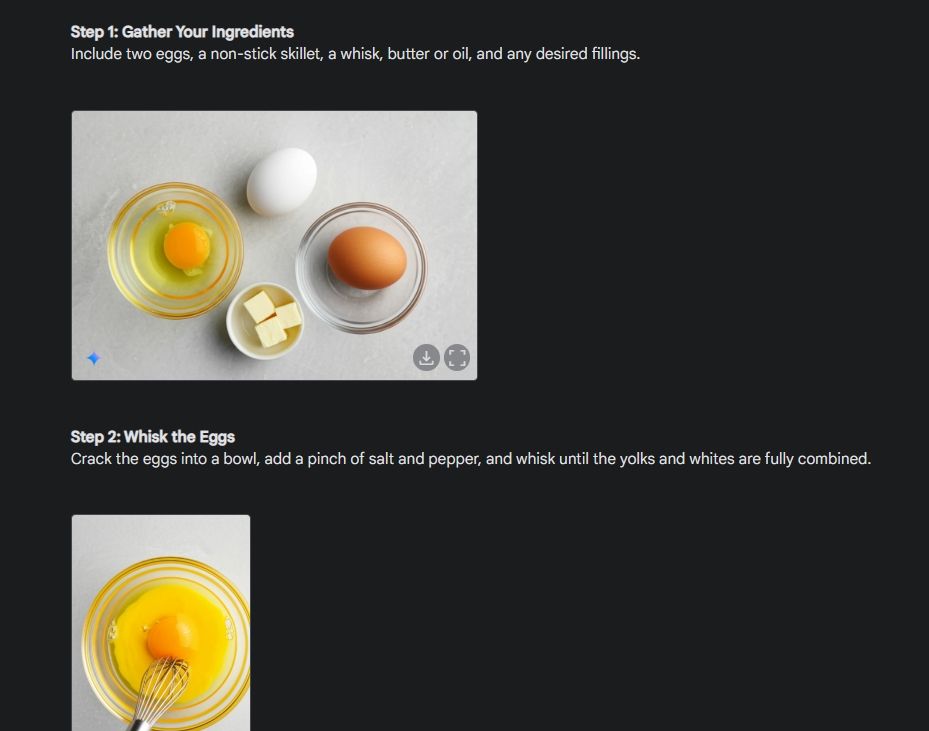
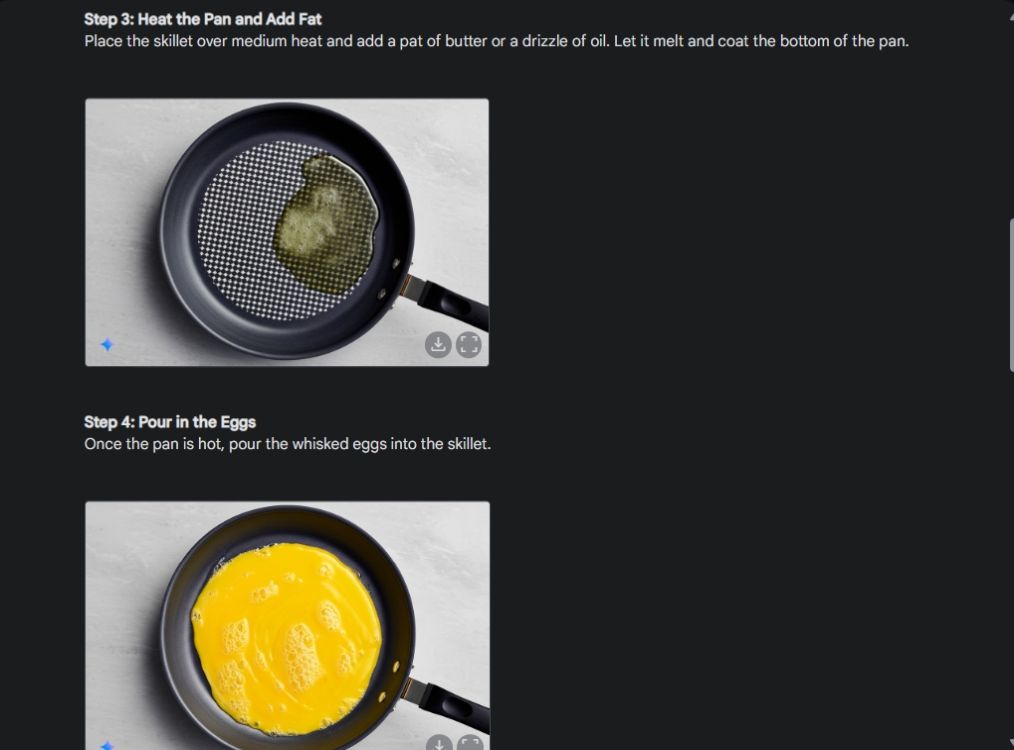

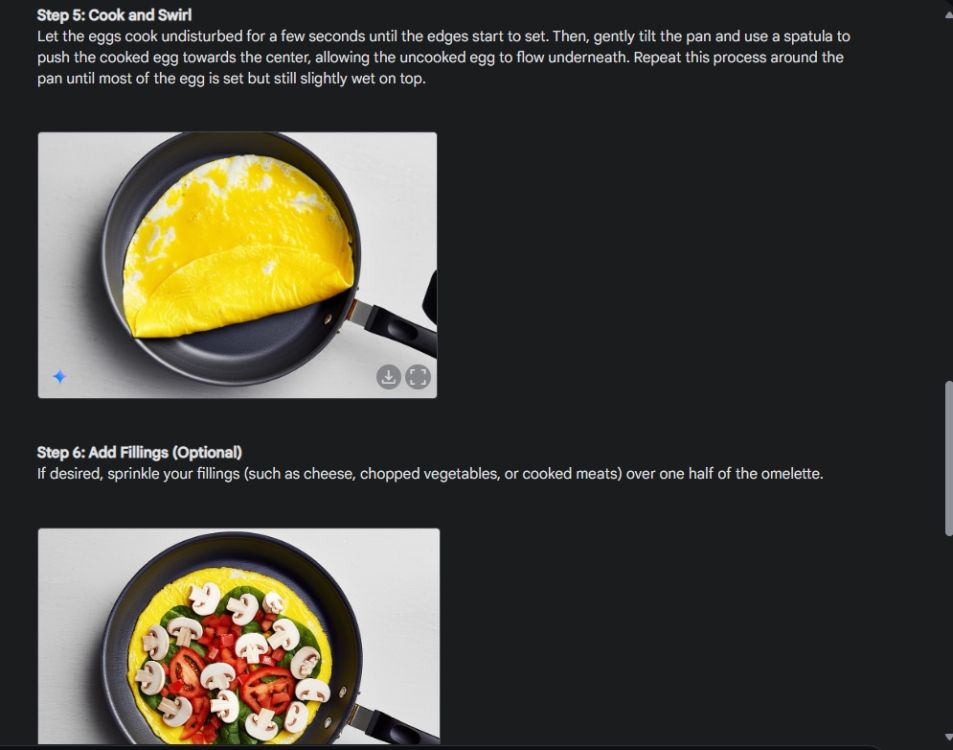
ご覧のとおり、結果は画像間で非常に一貫しており、エラーはありません。ボウルも1024枚目の写真と同じです。最後に、680 x XNUMX 解像度の画像をダウンロードできます。この方法により、必要なものすべてに対する視覚的なガイドを作成できます。
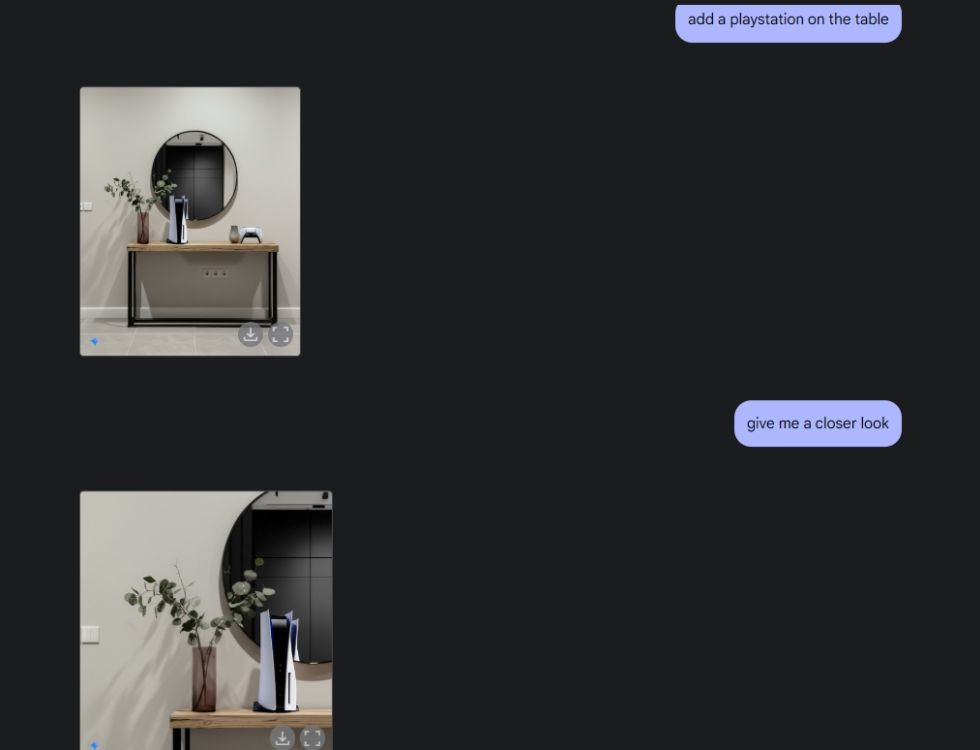
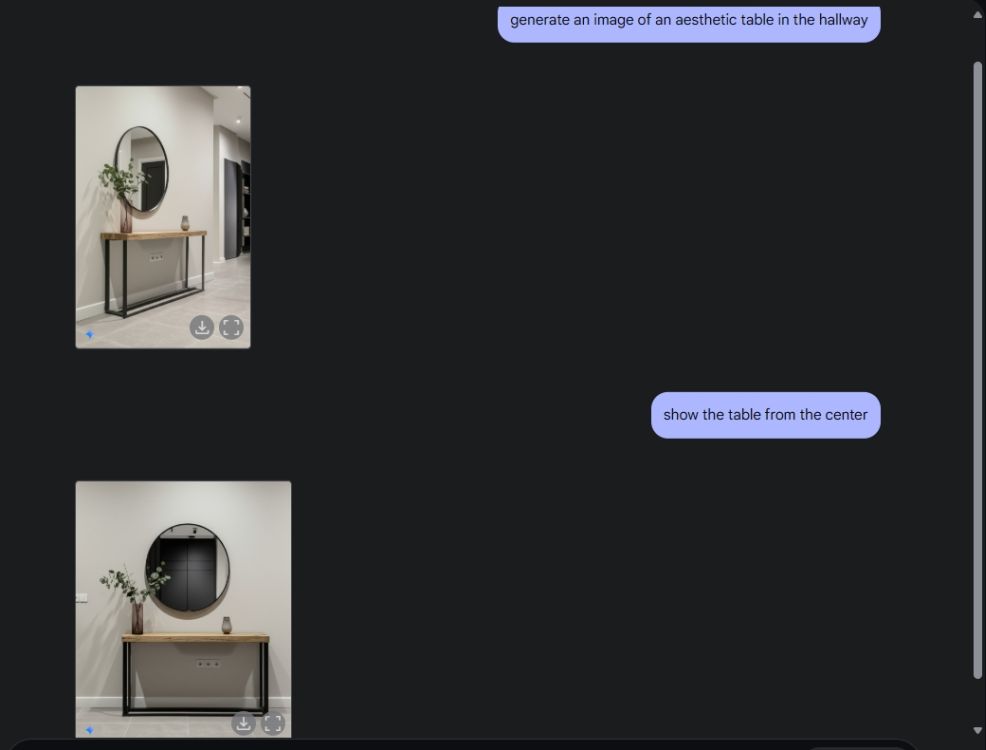
次に、Gemini に美しいテーブル画像を作成するように依頼し、中央のカメラアングルからテーブルを表示するように依頼しました。彼は完璧な仕事をした。次に、ジェミニにプレイステーションをテーブルに置いてもらい、よく見てみました。もう一度、ジェミニは成功しました。下記のように、AIモデルには背後の鏡に映ったPS5の映像も組み込まれていました。
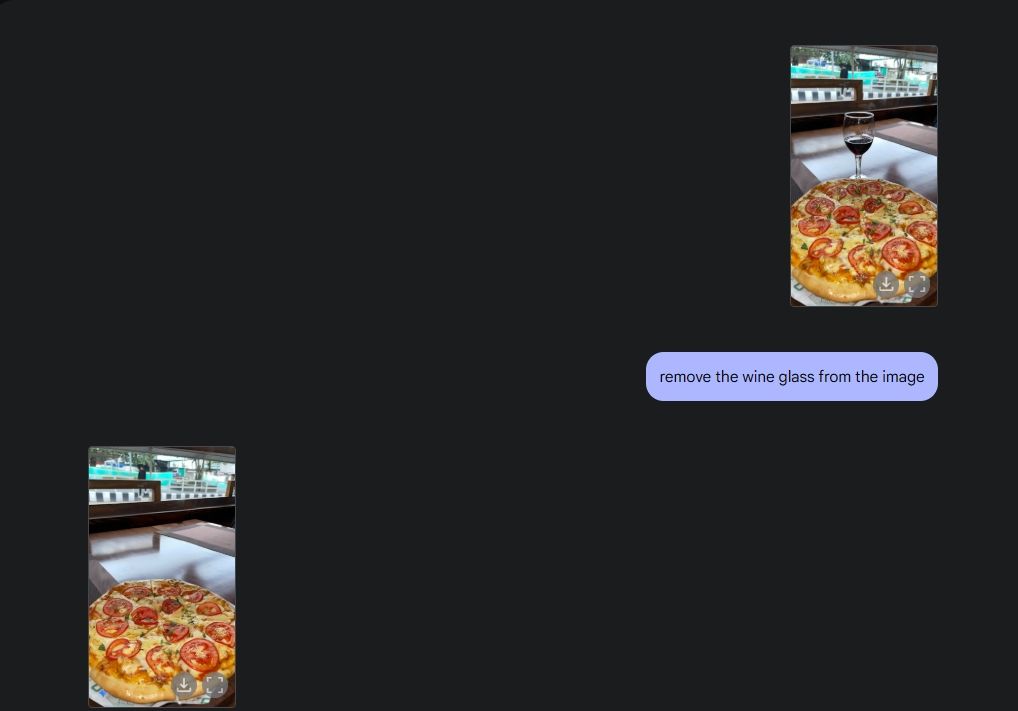
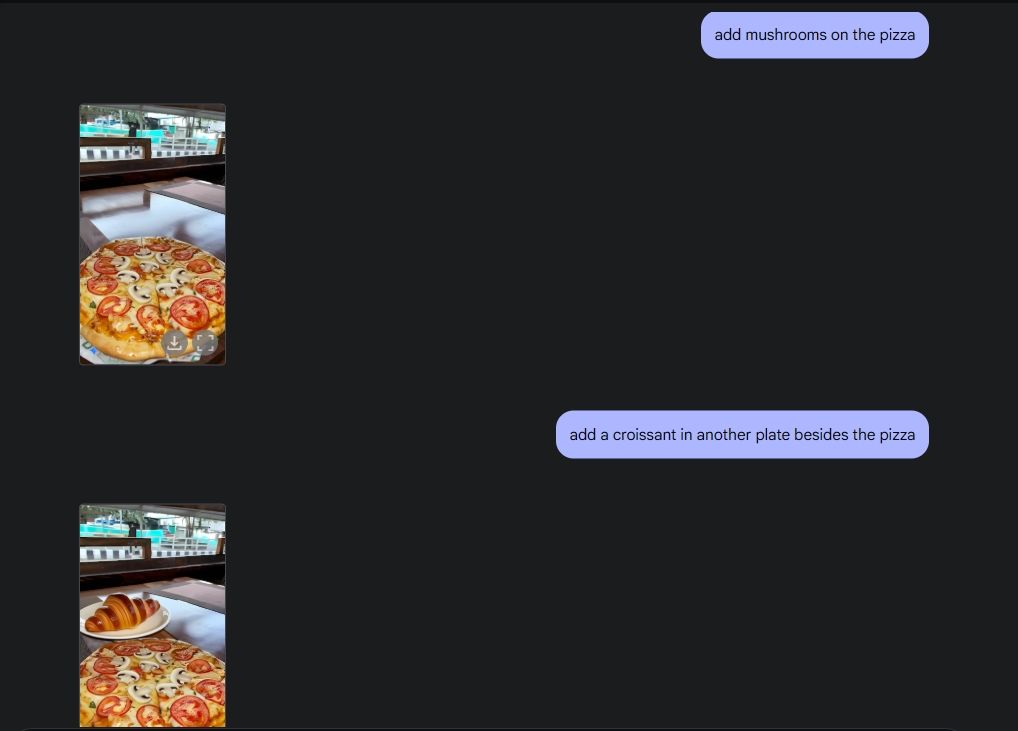
オリジナルの写真編集を実演するために、ギャラリーから写真をアップロードし、Gemini 2.0 にテーブルからワイングラスを削除するように指示しました。次に、ジェミニにピザにマッシュルームを追加するよう頼みましたが、彼は素晴らしい出来栄えでした。次に、Gemini にクロワッサンを追加するように依頼しました。これで、Gemini のマルチメディア機能のおかげで、すべての機能を備えた AI 写真編集が完成しました。
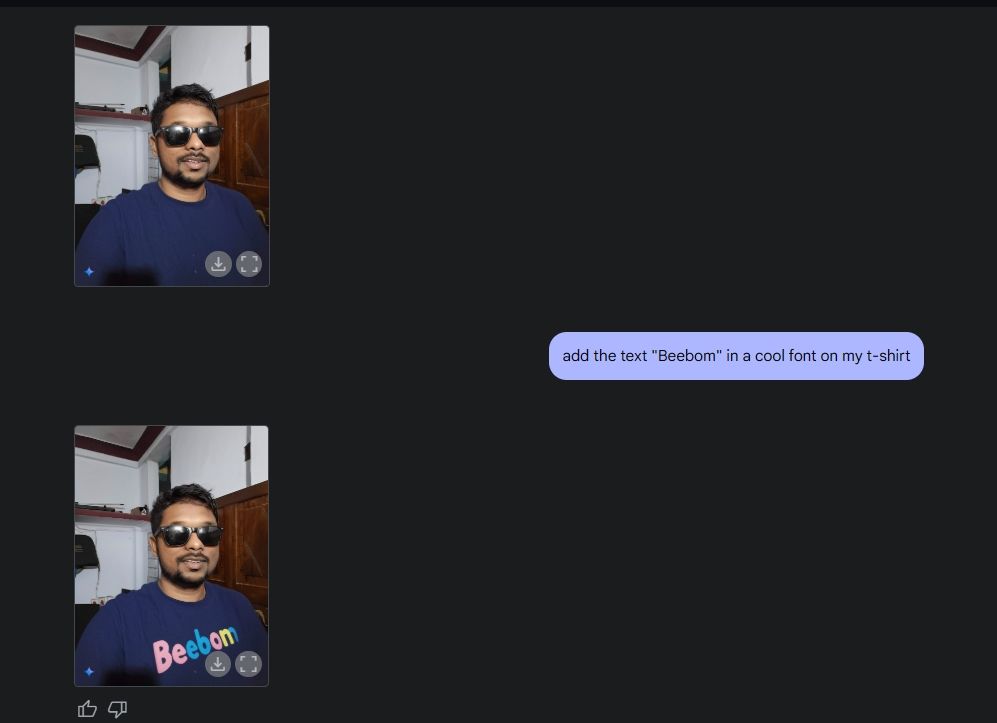
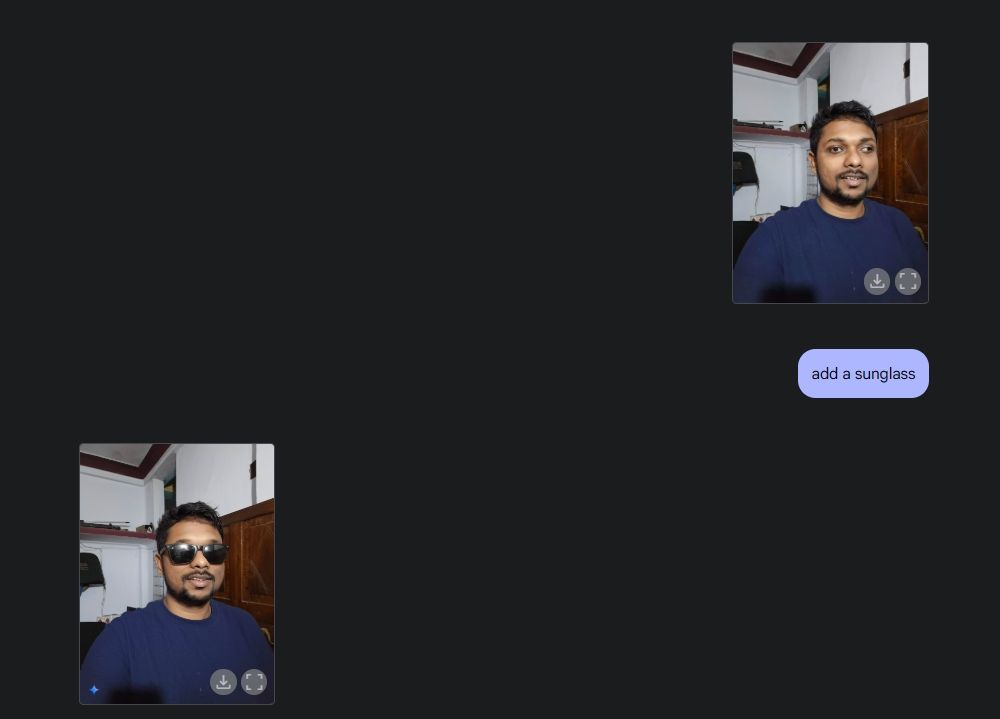
次に、自分の写真をアップロードし、Gemini にサングラスを追加してもらい、シャツに「Beebom」というテキストを追加しました。どちらも非常にうまく実行されました。
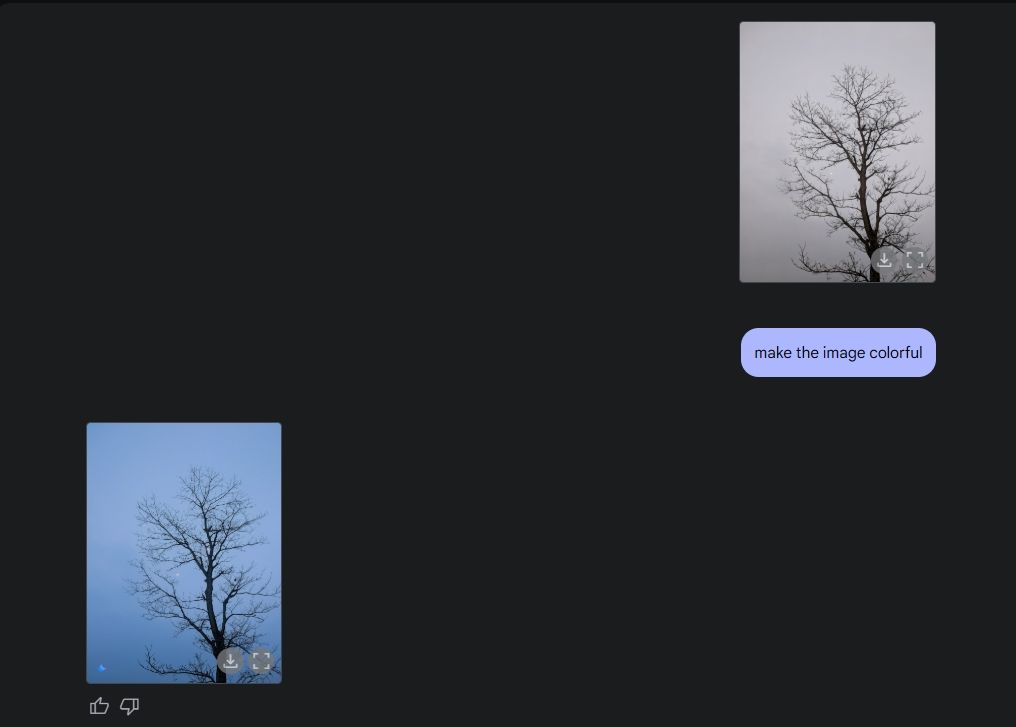
最後に、ジェミニに絵に色を塗るように頼みましたが、これも上手にできました。つまり、写真は以前よりも美しく、奇妙なエラーや歪み、画像の一部が欠けることもありません。
Gemini の新しいマルチメディア機能で体験できるユースケースは数多くあります。 Google はネイティブ画像の作成と編集に関して素晴らしい仕事をしており、私は今後数週間でこれをさらに徹底的に使用してその限界をテストするつもりです。
Google は、ビデオ作成用の Veo 2 と特殊な画像作成用の Imagen 3 をリリースした後、多くの分野で OpenAI を上回ったようです。 AIテキスト生成の分野だけではありません。したがって、OpenAI が ChatGPT で再びリードを得るために何をするのかを見るのは興味深いでしょう。
コメントは締め切りました。