

世界は 人工知能 (AI) 不安定な領域のように思われがちですが、舞台裏では企業自身だけでなく、独自のランキングを決定するために作られたグループによっても、驚くほど多くの分析、ベンチマーク、テストが行われています。

これらのグループは、チャットボットが数学のテストを完了する能力から、
画像の作成、論理的な説明をしたり、医学的なアドバイスをしたり、あるいは単に彼女が感情的にどれほど知的なのかを示したりすることもできます。
これらの様々なテストを通して、モデルは様々な領域で強みと弱みを示す。例えば、 GPT-5 彼は科学的推論に優れていますが、新しい概念に適応する能力ではジェミニやクロードなどに遅れをとっています。
これらのテストはどれもAIモデルに関する新たな知見を提供し、様々なシナリオにおいてどのツールが最適かを思い出させる上で重要です。しかし、多くの場合、一つの指標が欠けています。それは、どのAIモデルが最高のユーザーエクスペリエンスを提供するのかということです。
人道的分類システム
英国に拠点を置くテクノロジー企業Prolificは 「Humaine」と呼ばれるAIリーダーボードProlific は、AI がタスクを完了する能力をテストする代わりに、これらのモデルを使用してさまざまなユーザー エクスペリエンスをテストしました。
21,352人のツール使用体験を評価することで、総合的な勝者を見つけることができただけでなく、年齢、場所(テストは英国と米国の両方で行われた)、政治的信条ごとに結果を分類することもできました。
これには以下の個別のリストが含まれます。
- 英国: 年齢層
- イギリス:人種
- 英国:政治的視点
- アメリカ合衆国: 年齢層
- アメリカ合衆国:人種
- アメリカ合衆国:政治的視点
チームは、各参加者に 2 つの異なる AI モデルを比較してもらい、それぞれのインタラクションでどちらのモデルのパフォーマンスが優れているかについてのフィードバックを求めました。
その結果、パフォーマンスの総合優勝者とリーダーボードが誕生しただけでなく、基本的なタスクのパフォーマンスと推論に関する個別のランキング、さらにコミュニケーション、回復力、信頼、倫理に関する優勝者も誕生しました。
結果は何を示していますか?

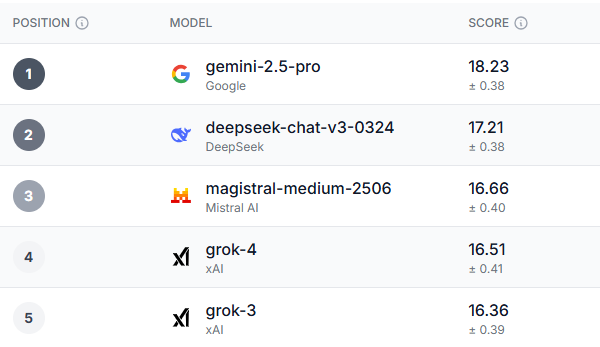
徹底的なレビューの結果、総合的なパフォーマンスカテゴリーだけでなく、ほとんどのサブカテゴリーにおいても、明確な勝者が決定しました。Gemini 2.5-Proは、テスト対象となったほぼすべてのベンチマークで優れた性能を発揮しました。
英国の18~34歳の若者、民主党支持者、米国の55歳以上の人々は、 ジェミニ 2.5 プロ 総合的に見て最も優れたモデルです。すべての人口統計においてGeminiよりも高い評価を得たのは、信頼、倫理、安全性の3つだけで、Grok-3でした。これは、近年AIモデルが直面している安全性と倫理に関する問題を考えると、やや皮肉な結果です。
興味深いことに、ジェミニの後に登場した3つのモデルは、ディープシーク、マジストラル・ル・シャット、そして グロクDeepseekは今年初めに大きな人気を博しましたが、最近は人気が下がっています。一方、Le Chatはそれほど人気のないチャットボットですが、熱心なファンベースを持っています。
では、世界的に有名なChatGPTは、この中でどこに位置づけられるのでしょうか?リストの最下位、GPT-4.1モデルとしては最高評価の8位に位置しています。さらにひどいのは、 クロード、その4回の大会は総合順位で11位と12位にランクされました。
それで、これは何を意味するのでしょうか?
これは、Geminiが世界最高のAIチャットボットだという意味でしょうか?それとも、ChatGPTはもうやめるべきなのでしょうか?まあ、必ずしもそうではありません。
これらの結果は必ずしもこれらのモデルのパフォーマンスを反映するものではありません。他のほとんどの指標でテストした場合、上位に表示される選択肢は通常、ChatGPT、Gemini、Claude、Grokです。
しかし、これはこれらのテストに重要な追加要素となります。人間の経験という観点からAIをより深く理解するのに役立ちます。例えば、Le Chatは標準的なベンチマークでは高いスコアを獲得していませんが、経験と信頼性の点では優れた選択肢としてよく挙げられます。
AnthropicとOpenAIのパフォーマンスは今回のテストではこのレベルには達しませんでしたが、GeminiとGrokは今回も素晴らしいパフォーマンスを見せました。両社とも標準的なベンチマークで高いスコアを達成することが多く、今回もその調子を維持しました。
コメントは締め切りました。