

セルフアクションAIガイド:AIエージェント構築への旅を始めましょう
AI エージェントを作成する方法の基本を学びます。これらのインテリジェント システムを設計および実装するために必要なツールとテクニックについて説明します。
人工知能業界は急速な発展を遂げています。それは印象的で、しばしば混乱を招きます。
データ サイエンスの将来は生成 AI の開発と密接に関係していると信じているため、私はデータ サイエンスのこの分野を研究し、学習し、基礎を築いてきました。
初めて作ったのは昨日のことのようです AIエージェントそして2週間後には、多くのPythonパッケージから選択できるようになり、また、次のような非常に優れたパフォーマンスを発揮するノーコードオプションも登場しました。 n8n.

私たちとチャットできる単なるモデルから、インターネットを検索し、ファイルを処理し、プロジェクトを実行する、あらゆる場所にいる AI エージェントの津波まで。 データサイエンス プロセス全体(初期のデータ探索からモデリングと評価まで)は、わずか数年で完了しました。
何?
これらすべてを見て、私はこう思いました。 「できるだけ早く参加する必要があります。」。結局、波に飲み込まれるよりも波に乗る方が良いのです。
このため、私はこのシリーズの投稿を開始することに決め、基礎から最初の AI エージェントの構築、そしてより複雑な概念に至るまでを説明する予定です。
話はこれくらいにして、始めましょう。
AIエージェントの基礎
AI エージェントは、大規模言語モデル (LLM) にツールと対話し、役立つアクションを実行する機能を与えることで作成されます。単なるチャットボットではなく、予定の作成、カレンダーの管理、インターネットの検索、ソーシャルメディアへの投稿など、さまざまな機能を使用できるようになりました。この変革により、本格的なデジタルアシスタントになりました。
AI 搭載エージェントは、チャットだけでなく、便利な機能も実行できます。
しかし、大規模言語モデル (LLM) にこの能力を与えるにはどうすればよいのでしょうか?
簡単な答えは、API を使用して大規模言語モデルと対話することです。最近ではこれに対応した Python パッケージが数多くあります。私のブログをフォローしていれば、私がすでにエージェントを作成するためのパッケージをいくつか試していることがわかります。たとえば、Langchain、Agno (旧称 Phidata)、CrewAI などです。このシリーズでは、アグノ[1]を取り上げたいと思います。
まず、仮想環境をセットアップします。 uv あるいは、Anaconda またはお気に入りの環境プロセッサ。次に、パッケージをインストールします。
# Agno AI
pip install agno
# module to interact with Gemini
pip install google-generativeai
# Install these other packages that will be needed throughout the tutorial
pip install agno groq lancedb sentence-transformers tantivy youtube-transcript-api先に進む前に、少し注意事項があります。 Google Gemini APIキー[2]を取得することを忘れないでください。
シンプルなプロキシの作成は非常に簡単です。すべてのパッケージは非常に似ています。彼らにはクラスがあります。 Agent または、モデルを選択し、選択したより大きな言語モデルとの対話を開始できる同様のもの。このカテゴリの主なコンポーネントは次のとおりです。
model:大規模言語モデルに接続します。ここでは、OpenAI、Gemini、Llama、Deepseek などの中から選択します。descriptionこのパラメータを使用すると、エージェントの動作を記述できます。これは、system_messageも同様の媒体です。instructionsエージェントとは、私たちが管理する従業員またはアシスタントであると考えるのが好きです。タスクを達成するには、何をすべきかについての指示を与える必要があります。ここでそれができます。expected_outputここでは、期待される出力に関する指示を提供できます。toolsこれにより、大規模言語モデルがエージェントとなり、これらのツールを使用して現実世界と対話できるようになります。
ここで、ツールはありませんが、コード構造に関する直感を養うのに役立つシンプルなエージェントを作成しましょう。
# Imports
from agno.agent import Agent
from agno.models.google import Gemini
import os
# Create agent
agent = Agent(
model= Gemini(id="gemini-1.5-flash",
api_key = os.environ.get("GEMINI_API_KEY")),
description= "An assistant agent",
instructions= ["Be sucint. Answer in a maximum of 2 sentences."],
markdown= True
)
# Run agent
response = agent.run("What's the weather like in NYC in May?")
# Print response
print(response.content)## ...
ニューヨークの5月の気温は、通常華氏50度前半から70度半ばの穏やかな気温になるでしょう。 雨が降る可能性がありますので、重ね着をして傘をお持ちいただくことをお勧めします。
これは素晴らしいですね。私たちはGemini 1.5モデルを使用しています。トレーニングに使用されたデータに基づいてどのように応答するかに注目してください。今日の天気を尋ねると、インターネットにアクセスできないという応答が表示されます。
仲介者について調べてみましょう。 instructions و expected_output。ここで、ニューヨーク市 (NYC) の月、季節、平均気温を示す表が必要です。
# Imports
from agno.agent import Agent
from agno.models.google import Gemini
import os
# Create agent
agent = Agent(
model= Gemini(id="gemini-1.5-flash",
api_key = os.environ.get("GEMINI_API_KEY")),
description= "An assistant agent",
instructions= ["Be sucint. Return a markdown table"],
expected_output= "A table with month, season and average temperature",
markdown= True
)
# Run agent
response = agent.run("What's the weather like in NYC for each month of the year?")
# Print response
print(response.content)
そしてこれが結果です。
| 月曜日 | 季節 | 平均気温(°F) |
|---|---|---|
| 1月 | 冬 | 32 |
| 2月 | 冬 | 35 |
| 3月 | 春 | 44 |
| 4月 | 春 | 54 |
| 5月 | 春 | 63 |
| 6月 | 夏 | 72 |
| 7月 | 夏 | 77 |
| 8月 | 夏 | 76 |
| 9月 | 秋 | 70 |
| 10月 | 秋 | 58 |
| November | 秋 | 48 |
| 12月 | 冬 | 37 |
أدوات
上記の答えは良いのですが、もちろん、強力な大規模言語モデル (LLM) を使用してチャットボットを操作したり、古いニュースを教えてくれたりしたくないですよね?
私たちは、それが自動化、生産性、知識への架け橋となることを望んでいます。そこで、 أدوات AI エージェントに機能を追加し、現実世界との架け橋を構築します。エージェントの一般的な例としては、Web の検索、SQL の実行、電子メールの送信、API の呼び出しなどがあります。
しかし、それ以上に、任意の Python 関数をツールとして使用してエージェントのカスタム機能を作成できるため、さまざまなシステムやプロセスとの統合の可能性が大きく広がります。
ツール これらは、エージェントがタスクを実行するために実行できる関数です。
コードの観点から言えば、エージェントにウィジェットを追加するのは、ミドルウェアを使用するだけです。 tools カテゴリ内 Agent.
コンテンツ作成を自動化したいと考えている健康とウェルネス分野の個人事業主(一人経営の企業)を想像してください。この人は健康的な習慣についてのヒントを毎日投稿しています。コンテンツの作成は見た目ほど簡単ではないことは私も知っています。創造力、リサーチ、コピーライティングのスキルが必要です。したがって、自動化、または少なくとも一部を自動化できれば、時間の節約になります。
そこで、シンプルな Instagram 投稿を作成し、それをレビュー用に Markdown ファイルに保存できる非常にシンプルなエージェントを作成するために、このコードを記述します。プロセスが、考える > 調査する > 書く > レビューする > 公開するから、レビューする > 公開するに短縮されました。
# Imports
import os
from agno.agent import Agent
from agno.models.google import Gemini
from agno.tools.file import FileTools
# Create agent
agent = Agent(
model= Gemini(id="gemini-1.5-flash",
api_key = os.environ.get("GEMINI_API_KEY")),
description= "You are a social media marketer specialized in creating engaging content.",
tools=[FileTools(
read_files=True,
save_files=True
)],
show_tool_calls=True)
# Writing and saving a file
agent.print_response("""Write a short post for instagram with tips and tricks
that positions me as an authority in healthy eating
and save it to a file named 'post.txt'.""",
markdown=True)その結果、次のようになりました。
健康的な食事をすることでポジティブなエネルギーを解き放ちましょう。
1. 自然食品を優先する: 果物、野菜、赤身のタンパク質、全粒穀物をたくさん食べましょう。 栄養が豊富で、満腹感と活力を与えてくれます。
2. 意識して食べる: 体の空腹感と満腹感の信号に注意を払います。 食事中に気を散らすものを避けてください。
3. 水をたくさん飲む: 水は消化、エネルギーレベル、全体的な健康に不可欠です。.
4. 自分を制限しないでください。時々は甘いものを自分に許可してください。 欠乏は後で過食につながる可能性があります。 何事もほどほどに楽しみましょう!
5. 事前に計画を立てる: 不健康な選択を避けるために、食事や軽食を事前に準備します。
#健康的な食事 #健康的なライフスタイル #栄養 #食べ物好き #健康とウェルネス #健康的なヒント #クリーンイーティング #減量 #健康的なレシピ #栄養のヒント #インスタントヘルス #健康的な食べ物 #マインドフルイーティング #健康的な旅 #健康コーチ
もちろん、ウェブサイトのコンテンツのリストを検索するエージェント、コンテンツのチェッカーとレビュー担当者、投稿用の画像を作成するエージェントなど、他のエージェントでチームを作成することで、より複雑にすることもできます。しかし、追加する方法の一般的なアイデアは理解できたと思います tool 私に Agent.
追加できる別の種類のツールは次のとおりです。 道具 関数ツール。 Python 関数を使用して、大規模言語モデル (LLM) のツールとして機能させることができます。次のような型ヒントを追加することを忘れないでください。 video_id:strこれにより、モデルは関数への入力として何を使用するかを認識します。そうしないと、エラーが表示される場合があります。
これがどのように機能するかを簡単に見てみましょう。
ここで、エージェントが特定の YouTube 動画を取得して要約できるようにしたいと考えています。このようなタスクを実行するには、YT からビデオのトランスクリプトをダウンロードし、それを要約のためにモデルに渡す関数を作成するだけです。
# Imports
import os
from agno.agent import Agent
from agno.models.google import Gemini
from youtube_transcript_api import YouTubeTranscriptApi
# Get YT transcript
def get_yt_transcript(video_id:str) -> str:
"""
Use this function to get the transcript from a YouTube video using the video id.
Parameters
----------
video_id : str
The id of the YouTube video.
Returns
-------
str
The transcript of the video.
"""
# Instantiate
ytt_api = YouTubeTranscriptApi()
# Fetch
yt = ytt_api.fetch(video_id)
# Return
return ''.join([line.text for line in yt])
# Create agent
agent = Agent(
model= Gemini(id="gemini-1.5-flash",
api_key = os.environ.get("GEMINI_API_KEY")),
description= "You are an assistant that summarizes YouTube videos.",
tools=[get_yt_transcript],
expected_output= "A summary of the video with the 5 main points and 2 questions for me to test my understanding.",
markdown=True,
show_tool_calls=True)
# Run agent
agent.print_response("""Summarize the text of the video with the id 'hrZSfMly_Ck' """,
markdown=True)すると結果が得られます。
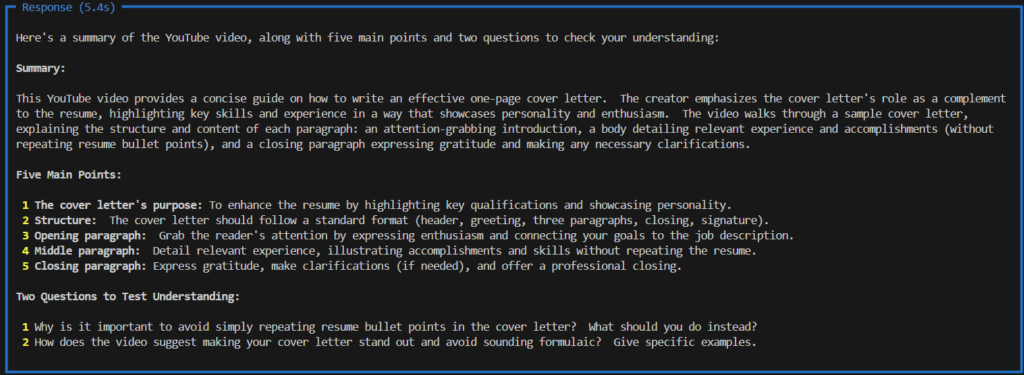
推論能力を持つエージェント
Agno が提供するもう 1 つの優れたオプションは、質問に答える前に状況を分析できるエージェントを作成できることです。これは推論ツールです。確認する AIエージェントの種類と用途:詳細な説明.
Alibaba の Qwen-qwq-32b モデルを使用して推論エージェントを作成します。ここでの唯一の違いは、モデル以外にウィジェットを追加していることであることに注意してください。 ReasoningTools()。このツールにより、エージェントは回答を提供する前に論理的に考えることができます。
財産とは adding_instructions=True エージェントに詳細な指示を提供することで、ツールの使用における信頼性と正確性が向上します。このプロパティを設定すると、次のようになります: False エージェントが自分の推論に頼らざるを得なくなるため、エラーが発生しやすくなる可能性があります。これにより、モデルの機能を個別に評価できるようになります。
# Imports
import os
from agno.agent import Agent
from agno.models.groq import Groq
from agno.tools.reasoning import ReasoningTools
# Create agent with reasoning
agent = Agent(
model= Groq(id="qwen-qwq-32b",
api_key = os.environ.get("GROQ_API_KEY")),
description= "You are an experienced math teacher.",
tools=[ReasoningTools(add_instructions=True)],
show_tool_calls=True)
# Writing and saving a file
agent.print_response("""Explain the concept of sin and cosine in simple terms.""",
stream=True,
show_full_reasoning=True,
markdown=True)出力は以下の通りです。
知識提供エージェント
このツールは、Recovery Augmented Generation (RAG) システムを作成する最も簡単な方法です。この機能を使用すると、エージェントを Web サイトまたは Web サイトのリストに誘導することができ、エージェントはコンテンツをベクター データベースに追加します。その後、コンテンツは検索可能になります。プロンプトが表示されたら、エージェントはそのコンテンツを回答の一部として使用できます。この技術により、AI の回答の精度と信頼性が向上します。
この簡単な例では、自分の Web サイトから 1 ページを追加し、そこにどのような書籍がリストされているかをエージェントに尋ねました。エージェントが情報にアクセスして使用する方法について説明します。
# Imports
import os
from agno.agent import Agent
from agno.models.google import Gemini
from agno.knowledge.url import UrlKnowledge
from agno.vectordb.lancedb import LanceDb, SearchType
from agno.embedder.sentence_transformer import SentenceTransformerEmbedder
# Load webpage to the knowledge base
agent_knowledge = UrlKnowledge(
urls=["https://gustavorsantos.me/?page_id=47"],
vector_db=LanceDb(
uri="tmp/lancedb",
table_name="projects",
search_type=SearchType.hybrid,
# Use Sentence Transformer for embeddings
embedder=SentenceTransformerEmbedder(),
),
)
# Create agent
agent = Agent(
model=Gemini(id="gemini-2.0-flash", api_key=os.environ.get("GEMINI_API_KEY")),
instructions=[
"Use tables to display data.",
"Search your knowledge before answering the question.",
"Only inlcude the content from the agent_knowledge base table 'projects'",
"Only include the output in your response. No other text.",
],
knowledge=agent_knowledge,
add_datetime_to_instructions=True,
markdown=True,
)
if __name__ == "__main__":
# Load the knowledge base, you can comment out after first run
# Set recreate to True to recreate the knowledge base if needed
agent.knowledge.load(recreate=False)
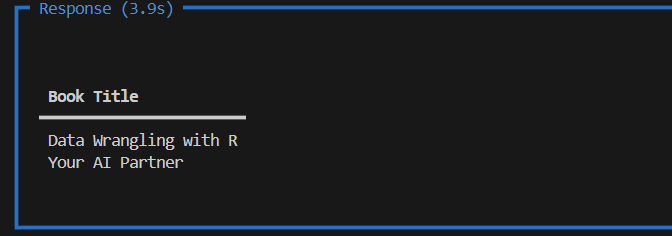
agent.print_response(
"What are the two books listed in the 'agent_knowledge'",
stream=True,
show_full_reasoning=True,
stream_intermediate_steps=True,
)
メモリ対応エージェント
この記事で最後に取り上げるタイプは、AI エージェントの分野における基本的な概念であるメモリ対応エージェントです。
このタイプのエージェントには、以前のやり取りからユーザーに関する情報を保存および取得する機能があり、ユーザーの好みを理解して応答をパーソナライズすることができます。このメモリにより、エージェントはその後のやり取りでより効果的になります。
エージェントにいくつかのことを伝え、そのやり取りに基づいて推奨事項を尋ねる例を見てみましょう。これは、メモリ対応エージェントがユーザー エクスペリエンスをどのように向上できるかを示しています。
# imports
import os
from agno.agent import Agent
from agno.memory.v2.db.sqlite import SqliteMemoryDb
from agno.memory.v2.memory import Memory
from agno.models.google import Gemini
from rich.pretty import pprint
# User Name
user_id = "data_scientist"
# Creating a memory database
memory = Memory(
db=SqliteMemoryDb(table_name="memory",
db_file="tmp/memory.db"),
model=Gemini(id="gemini-2.0-flash",
api_key=os.environ.get("GEMINI_API_KEY"))
)
# Clear the memory before start
memory.clear()
# Create the agent
agent = Agent(
model=Gemini(id="gemini-2.0-flash", api_key=os.environ.get("GEMINI_API_KEY")),
user_id=user_id,
memory=memory,
# Enable the Agent to dynamically create and manage user memories
enable_agentic_memory=True,
add_datetime_to_instructions=True,
markdown=True,
)
# Run the code
if __name__ == "__main__":
agent.print_response("My name is Gustavo and I am a Data Scientist learning about AI Agents.")
memories = memory.get_user_memories(user_id=user_id)
print(f"Memories about {user_id}:")
pprint(memories)
agent.print_response("What topic should I study about?")
agent.print_response("I write articles for Towards Data Science.")
print(f"Memories about {user_id}:")
pprint(memories)
agent.print_response("Where should I post my next article?")
これで、この最初の記事を終わります。 人工知能エージェント。この記事が、さまざまな種類の AI エージェントについての役立つ概要を提供できたことを願っています。
出発前に
この記事には多くの情報が含まれています。 AIエージェントの学習への第一歩を踏み出しました。混乱してしまうこともあるでしょうし、世の中には情報が多すぎて、どこから始めればいいのか、何を勉強すればいいのかがわからないこともあります。
私の提案は、私が取っているのと同じルートを取ることです。一度に 1 ステップずつ、Agno や CrewAI などのパッケージをいくつか選択して詳しく調べ、そのたびにより複雑なエージェントを作成する方法を学習します。この段階的なアプローチは、複雑な AI の概念を理解するのに最適です。
この記事では、ゼロから始めて、大規模言語モデル (LLM) と簡単に対話する方法から、メモリを備えたエージェントの作成、さらには AI エージェント用のシンプルな検索拡張 (RAG) システムの作成までを学習しました。これらの基本的なスキルは、AI エージェントがどのように機能するかを理解するために不可欠です。
明らかに、エージェント 4 台だけでもできることはたくさんあります。より高度な例については参考文献[XNUMX]を参照してください。
これらの簡単なスキルがあれば、あなたはきっと多くの人より先に進むことができ、すでにできることがたくさんあります。創造力を活かしてみませんか?素晴らしいものを作るために、大規模な言語モデルに助けを求めましょう。 AI ツールを使用して創造性を高めます。
次の記事では、AIエージェントとその評価についてさらに詳しく見ていきます。お楽しみに!
GitHub リポジトリ
https://github.com/gurezende/agno-ai-labs
参照
【1] https://docs.agno.com/introduction
【2] https://ai.google.dev/gemini-api/docs
【3] https://pypi.org/project/youtube-transcript-api/
【4] https://github.com/agno-agi/agno/tree/main/cookbook
【5] https://docs.agno.com/introduction/agents#agent-with-knowledge
コメントは締め切りました。