

OllamaとOpenAIのsimple-evalsを使用したGPQAでのDeepSeek-R1蒸留モデルの性能評価
ローカルで抽出された DeepSeek-R1 モデルで GPQA-Diamond ベンチマークを設定して実行し、推論機能を評価します。
最新モデルの発売 ディープシーク-R1 世界中の AI コミュニティで広く共感を呼びました。 Meta や OpenAI の推論モデルに匹敵する画期的な成果を、わずかな時間とはるかに低いコストで達成しました。
しかし、見出しやオンラインでの誇大宣伝を超えて、認められた基準を使用してモデルの推論機能をどのように評価できるのでしょうか?これは AI の専門家にとって重要な質問です。
。 ユーザーインターフェース ディープシーク 機能の探索は簡単になりますが、プログラムで使用すると、より深い洞察が得られ、実際のアプリケーションへの統合がスムーズになります。これらのモデルがローカルでどのように動作するかを理解することで、制御とオフライン アクセスも向上します。

この記事では、 オラマ و OpenAIのsimple-evals ベンチマークに基づいてDeepSeek-R1蒸留モデルの推論能力を評価する GPQA ダイヤモンド 有名な。この基準は、論理的推論の分野で人工知能モデルを評価するための最も重要なツールの 1 つと考えられています。
あなたへ GitHubリポジトリリンク この記事に付随する。
(1)推論のモデルとは何か?
DeepSeek-R1 や OpenAI の o シリーズ モデル (o1、o3 など) などの推論モデルは、強化学習を使用してトレーニングされ推論を実行する大規模言語モデル (LLM) です。これらのモデルは人工知能の分野における高度なツールであり、論理的に考え、複雑な問題を解決する機械の能力の進化の頂点を表しています。
ヒューリスティックスは、答える前に深く考え、応答する前に長い一連の内部思考を生み出すという特徴があります。複雑な問題の解決、プログラミング、科学的推論、エージェント ワークフローの複数ステップの計画に優れています。これらの機能により、高度なソフトウェア開発、科学研究、複雑なプロセスの自動化などの分野では不可欠なものとなっています。
(2)DeepSeek-R2モデルとは何ですか?
DeepSeek-R1は、最先端のオープンソース大規模言語モデル(LLM)であり、特に以下の目的で設計されています。 高度な推論。 2025年XNUMX月に研究論文として提出 「DeepSeek-R1: 強化学習による大規模言語モデルの推論能力の向上「。 DeepSeek-R1 は人工知能分野における先駆的なモデルです。
このモデルは、671億のパラメータを持つ大規模言語モデル (LLM) アーキテクチャに基づいており、次のパスに基づいて広範な強化学習 (RL) を使用してトレーニングされました。
- 拡張の 2 つの段階は、改善された推論パターンを発見し、人間の好みに合わせることを目的としています。
- 2 段階の教師あり微調整は、モデルの推論機能と非推論機能のシードとして機能します。
説明のために、DeepSeek は次の 2 つのモデルをトレーニングしました。
- 最初のモデルは、 ディープシーク-R1-ゼロは強化学習を用いて訓練された推論モデルであり、2番目のモデルを訓練するためのデータを生成する。 ディープシーク-R1.
- これは推論トレースを生成することで実現され、最終結果に基づいて高品質の出力のみが保持されます。
- つまり、ほとんどのモデルとは異なり、このトレーニング パイプラインの強化学習 (RL) の例は人間によってキュレーションされるのではなく、モデル自体によって生成されます。
その結果、このモデルは次のような主要モデルと同様のパフォーマンスを達成しました。 OpenAIのo1モデル 数学、プログラミング、複雑な推論などのタスクにおいて。
(3)DeepSeek-R3からの蒸留プロセスと蒸留モデルの理解
完全なモデルに加えて、彼らはまた、異なるサイズ(1B、1.5B、7B、8B、14B、32B)の70つのより小さな高密度モデル(DeepSeek-R1とも呼ばれる)をオープンソース化した。これは、DeepSeek-RXNUMXに基づいて抽出されたものである。 クウェン أو ラマ 基本モデルとして。
蒸留 これは、より小さなモデル(「生徒」)を、以前にトレーニングされたより大きく強力なモデル(「教師」)のパフォーマンスを再現するようにトレーニングする手法です。
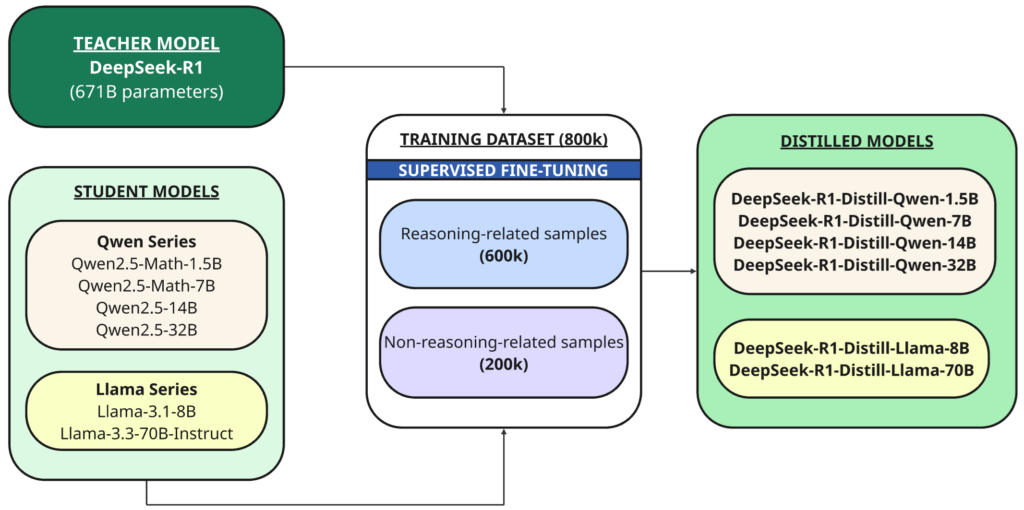
この場合、教師は 1B DeepSeek-R671 モデルであり、生徒は、このオープンソース ベース モデルを使用して抽出された XNUMX つのモデルです。
DeepSeek-R1を教師モデルとして使用し、推論サンプルと非推論サンプルの混合である800,000万のトレーニングサンプルを生成し、蒸留を行った。 監督付き微調整 基本モデル(1.5B、7B、8B、14B、32B、70B)用。
では、そもそもなぜ蒸留するのでしょうか?
目標は、DeepSeek-R1 671B などの大規模モデルの推論機能を、より小型で効率的なモデルに移転することです。これにより、より高速かつリソース効率の高い、より小規模なモデルで複雑な推論タスクを処理できるようになります。
さらに、DeepSeek-R1 には膨大な数のパラメータ (671 億) があるため、ほとんどのコンシューマー デバイスで実行するのは困難です。
最大統合メモリが 128 GB の最も強力な MacBook Pro でも、671 億のパラメータを持つモデルを実行するには不十分です。
そのため、蒸留モデルは計算リソースが限られたデバイスに展開する可能性を開きます。
達成 ナマケモノ オリジナルの 1 億パラメータの DeepSeek-R671 モデルをわずか 131 GB に量子化することで、サイズが 80% も削減されるという驚くべき成果です。しかし、131GB の VRAM 要件は、特にリソースが限られたデバイスで作業する開発者にとっては依然として大きな障害となります。この成果は、大規模な AI モデルをより幅広いユーザーが利用できるようにするための大きな一歩となります。
(4)最適な蒸留モデルの選択
蒸留モデルには 6 つの異なるサイズがあり、適切なモデルを決定するには、ローカル機器の機能に大きく依存します。
高性能 GPU や CPU を搭載し、最大限のパフォーマンスを必要とするユーザーにとって、より大型の DeepSeek-R1 モデル (32B 以上) が理想的です。Quantum 671B バージョンでも実行可能です。
ただし、リソースが限られている場合や、ビルド時間を短縮したい場合 (私のように) は、8B や 14B などの小さな蒸留バリアントの方が適しています。これにより、パフォーマンスとリソース要件のバランスが取れます。
このプロジェクトでは、精製された DeepSeek-R1 モデルを使用します。 クウェン-14Bこれは、発生したハードウェアの制限に対応します。 このモデル (14B) は、精度と速度のバランスに優れており、私の開発環境に最適です。
(5)大規模言語モデルの推論能力を評価する基準
大規模言語モデル (LLM) は通常、言語理解、コード生成、指示の遵守、質問への回答など、さまざまなタスクにおけるパフォーマンスを決定する標準化されたメトリックを使用して評価されます。一般的な例としては次のようなメトリックが挙げられます。 MMLU、و HumanEval、و MGSM。これらのメトリックは、大規模言語モデルの機能を評価するのに不可欠です。
大規模な言語モデルの推論能力を測定するには、推論に重点を置き、表面的なタスクを超えた、より困難なベンチマークが必要です。高度な推論能力の評価に重点を置いた一般的な例を以下に示します。
(i) AIME 2024試験:競争数学
- 準備 アメリカ招待数学試験(AIME)2024 数学的推論における大規模言語モデル (LLM) の機能を評価するための堅牢なベンチマーク。
- この試験は、複雑で多段階の問題が出題されるため、競技数学における大きな挑戦となります。この試験では、大規模な言語モデルが複雑な質問を理解し、高度な推論を適用し、正確な記号操作を実行する能力がテストされます。 AIME は、複雑な数学的問題を解決する能力を評価するための重要な尺度です。
(ii) コードフォース – 競争コード
- 起きる コードフォース標準 アルゴリズムのチャレンジで知られるプラットフォームである Codeforces の実際の競技プログラミング問題を使用して、大規模言語モデル (LLM) の推論能力を評価します。 Codeforces は、複雑な問題を解決する AI モデルの能力を評価するためのゴールド スタンダードです。
- これらの問題は、複雑な命令を理解し、論理的および数学的な推論を実行し、複数ステップのソリューションを計画し、正確で効率的なコードを生成する大規模言語モデル (LLM) の能力をテストします。これらの問題を解決するには、アルゴリズムとデータ構造に関する深い理解と、問題を実行可能なコードに変換する能力が必要です。
(iii) GPQAダイヤモンド – 博士レベルの科学的質問
- GPQA-Diamondは、 最も難しい質問 標準から GPQA(大学院物理学の質問と回答) 最も幅広く、博士レベルの高度なトピックにおける LLM モデルの推論能力の限界を押し広げるために特別に設計されています。この標準は、複雑な科学的概念を理解し推論する AI の能力に対する真の挑戦を表しています。
- GPQA には概念的かつ計算ベースの大学院レベルの質問が含まれていますが、GPQA-Diamond では最も難しい質問と集中的な推論を必要とする質問のみが分離されています。
- この基準は「Google 耐性」があると考えられており、制限のない Web アクセスがあっても回答が難しいことを意味します。これにより、大規模な言語モデルが独立して推論する能力を評価するための貴重なツールになります。
- GPQA-Diamond の質問の例を次に示します。
### GPQA ダイヤモンド - 例題 (分子生物学) 真核細胞は高分子の構成要素をエネルギーに変換するメカニズムを進化させました。このプロセスは、細胞のエネルギー工場であるミトコンドリアで起こります。一連の酸化還元反応では、食物からのエネルギーがリン酸基の間に蓄えられ、細胞内の普遍的な通貨として使用されます。エネルギーを蓄えた分子はミトコンドリアから送り出され、あらゆる細胞プロセスに役立てられます。新しい抗糖尿病薬を発見し、それがミトコンドリアに影響を及ぼすかどうかを調査したいと考えています。 HEK293 細胞株を使用してさまざまな実験を設定します。以下の実験のうち、薬物のミトコンドリアにおける役割を発見するのに役立たないものはどれですか。(A) ミトコンドリアの分画遠心分離抽出とそれに続くグルコース取り込み比色アッセイキット (B) 2.5 µM 5,5',6,6'-テトラクロロ-1,1',3,3'-テトラエチルベンズイミダゾリルカルボシアニンヨウ化物で標識した後のフローサイトメトリー (C) 組換えルシフェラーゼによる細胞の形質転換と、上清に5 µM のルシフェリンを添加した後のルミノメーターによる読み取り (D) 細胞のミトコンドリアRTP染色後の共焦点蛍光顕微鏡検査
このプロジェクトでは、 結論の基準としてGPQA-Diamondを使用します。私が使ったとき OpenAI و ディープシーク 推論モデルを評価するため。評価基準として GPQA-Diamond が選ばれたことは、AI 開発分野におけるその難しさと重要性を証明しています。
(6)使用されたツール
このプロジェクトでは主に オラマ و シンプル評価 OpenAIより。 Ollama は大規模な言語モデルをローカルで実行するための強力なプラットフォームであり、simple-evals はこれらのモデルのパフォーマンスを評価するためのフレームワークを提供します。
(i) オラマ
オラマ これは、コンピューターまたはローカル サーバー上で大規模言語モデル (LLM) の実行を簡素化するオープン ソース ツールです。 Olama は、AI モデルをローカルで実行するのに最適なプラットフォームです。
マネージャーおよびランタイムとして機能し、ダウンロードや環境設定などのタスクを処理します。これにより、ユーザーは、常時インターネットに接続したり、クラウド サービスに依存したりすることなく、これらのモデルを操作できるようになります。ローカル大規模言語モデル (LLM) の管理は、Olama の中核機能です。
DeepSeek-R1 を含む多くの大規模なオープンソース言語モデルをサポートし、macOS、Windows、Linux とのクロスプラットフォーム互換性があります。さらに、手間を最小限に抑え、リソースを効率的に使用して簡単なセットアップを実現します。 Ollama を使用すると、デバイス上で人工知能のパワーを活用できます。
重要ローカルマシンに次のものがあることを確認してください: GPUアクセシビリティ Ollama の場合、これによりパフォーマンスが大幅に向上し、その後のベンチマークが CPU に比べて効率的になります。コマンドを実行する
nvidia-smiターミナルで GPU が検出されているかどうかを確認します。この手順により、デバイスの機能が最大限に活用され、モデルを高効率で実行できるようになります。
(ii) 言語モデルを評価するためのOpenAI simple-evalsライブラリ
準備する シンプル評価 思考連鎖プロンプトによるゼロショット評価手法を使用して言語モデルを評価するために設計された軽量ライブラリ。このライブラリには、MMLU、MATH、GPQA、MGSM、HumanEval などの一般的な評価ベンチマークが含まれており、実際の使用シナリオをシミュレートして、複雑な推論タスクにおける AI モデルのパフォーマンスを評価することを目的としています。
皆さんの中には、OpenAIの最も人気があり包括的な評価ライブラリである 評価これは simple-evals とは異なります。
実際、このページには README simple-evals 仕様は、ライブラリを置き換えることを意図していないことを示しています。 評価.
では、なぜ simple-eval を使用するのでしょうか?
簡単な答えは シンプル評価 このライブラリにはない、私たちがターゲットとする推論標準 (GPQA など) の評価テキストが組み込まれています。 評価.
さらに、 simple-evals 以外に、言語で直接的かつネイティブな方法を提供するツールやプラットフォームは見つかりませんでした。 Python 特に Ollama と連携する場合、GPQA などの多くの主要な標準を実行します。
(7)評価結果
評価の一環として、以下を選択しました。 ランダムな20の質問 GPQA-Diamondの198問の質問セットから フォーム14B 蒸留業者。合計で 216 分、つまり 11 問あたり約 XNUMX 分かかりました。
結果はやや残念なものだった。 10% のみであり、これは 73.3B DeepSeek-R1 モデルの報告された結果 671% よりも大幅に低いものです。
私が気づいた主な問題は、集中的な内部推論中に、 モデルは、多くの場合、回答を生成できない (例: 出力の最終行として推論コードを返す) か、予想される複数選択形式と一致しない応答 (例: 回答: A) を提供しました。
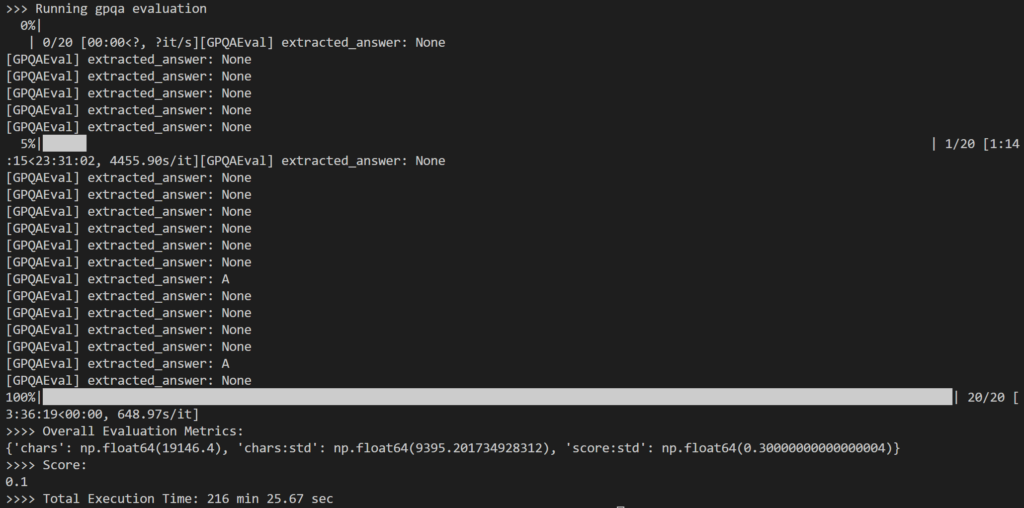
上記のように、出力の多くは次のようになりました。 None simple-evals の正規表現ロジックでは、LLM 応答で予想される回答パターンを検出できなかったためです。
その間 人間のような推論 質問に答える際の正確さという点ではより優れたパフォーマンスを期待していたので、観察するのは興味深いものでした。
また、オンラインのユーザーからは、より大きな 32B モデルでも o1 ほどには動作しないという意見も見ました。これにより、特に長い推論を生成したにもかかわらず正しい答えを出すのに苦労する場合、蒸留された推論モデルの有用性について疑問が生じています。
ただし、GPQA-Diamond は非常に要求の厳しいベンチマークであるため、これらのモデルはより単純な推論タスクには依然として役立つ可能性があります。計算要件が低いため、作業も簡単になります。
さらに、DeepSeek チームは、ベンチマーク プロセスの一環として複数のテストを実行し、結果を平均化することを推奨していましたが、時間の制約により私はこれを見落としていました。
(8)詳細なステップバイステップガイド
ここまで、基本的な概念と主な結論について説明しました。
実践的な技術体験をご希望の場合は、このセクションでは内部のメカニズムと段階的な実装について詳しく説明します。この実用的な技術ガイドは、システムがどのように動作するかを包括的に理解するのに役立ちます。
表示(またはコピー)するには コンパニオンGitHubリポジトリ フォローする。仮想環境のセットアップ要件については、こちらをご覧ください。 ここで.
(i) 初期設定 – Ollama
まずOllamaをダウンロードします。訪問
Ollama ダウンロードページ、オペレーティング システムを選択し、対応するインストール手順に従います。
インストールが完了したら、Ollamaアプリケーション(WindowsおよびmacOS)をダブルクリックするか、コマンドを実行してOllamaを起動します。 ollama serve ターミナル内。
(ii) 初期設定 – OpenAI simple-evals
simple-evals のセットアップは比較的ユニークです。
simple-evalsはライブラリとして機能しますが、 ファイルの不在 __init__.py リポジトリ内とは、適切な Python パッケージとして構造化されていないことを意味します。リポジトリをローカルにクローンした後にインポート エラーが発生します。つまり、これはソフトウェア エンジニアリングで一般的に使用される意味での標準 Python パッケージではないということです。
PyPIでも公開されておらず、次のような標準的なパッケージングファイルがないため、 setup.py أو pyproject.tomlインストールできません pip。これは、新しい開発者にとってはちょっとした挑戦となります。
幸いなことに、 Gitサブモジュール 直接的な代替ソリューションとして。これらのモジュールを使用すると、Git リポジトリを別のリポジトリに含めることができるため、依存関係の管理が容易になります。
「`html
Git サブモジュールを使用すると、プロジェクト内に別の Git リポジトリの内容を含めることができます。外部リポジトリ (simple-evals など) からファイルを取得しますが、履歴は別々に保持されます。
simple-eval の内容を抽出するには、次の 2 つの方法 (A または B) のいずれかを選択できます。
(a) 私のプロジェクトリポジトリをクローンした場合
私のプロジェクトリポジトリにはすでに simple-evals サブモジュールとして、次のコマンドを実行するだけです:
git submodule update --init --recursive(b) 新しく作成したプロジェクトに追加する場合。
simple-evals をサブモジュールとして手動で追加するには、次のコマンドを実行します。
git submodule add https://github.com/openai/simple-evals.git simple_evals通知: それ simple_evals 結局( アンダースコア)は非常に重要です。フォルダ名をハイフンを使って指定します(つまり、単純な–評価など) は、後でインポートの問題を引き起こす可能性があります。
最終ステップ(両方の方法とも)
リポジトリの内容をプルした後、ファイルを作成する必要があります。 __init__.py フォルダが空です simple_evals 新しく作成したものはユニットとしてインポートできます。手動で作成することも、次のコマンドを使用することもできます。
touch simple_evals/__init__.py(iii) Ollama経由でDeepSeek-R1モデルを取得する
次のステップでは、次のコマンドを使用して、選択したローカルで抽出されたモデル (たとえば、14B) をダウンロードします。
利用可能な DeepSeek-R1 モデルのリストは Ollama で確認できます。 ここで。最高のパフォーマンスを得るには、最新バージョンのテンプレートを使用することをお勧めします。
ollama pull deepseek-r1:14b(4番目)設定を指定する
設定 YAML ファイルで以下のようにパラメータを定義します。
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # モデル名(Ollama モデルリストと一致) MODEL_TEMPERATURE: 0.6 # DeepSeek-R0.5 の場合は 0.7 から 1 の間で設定 EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
モデル温度は 0.6 (一般的なデフォルト値 0 と比較)。これは、0.5 ~ 0.7 (0.6 が推奨) の温度範囲を提案する DeepSeek の使用推奨事項に従います。 無限の繰り返しや一貫性のない出力を防ぐため。 この設定は、出力の品質を向上させ、一貫性を確保するために必要です。
ぜひチェックしてみてください DeepSeek-R1のユニークで興味深い使用上の推奨事項 – 特にベンチマークの場合 – DeepSeek-R1 モデルを使用する際に最適なパフォーマンスを確保します。
EVAL_N_EXAMPLES これは、評価で使用される 198 個の質問の完全なセットから質問の数を設定するために使用されるパラメーターです。このパラメーターは、利用可能なリソースと特定のテスト目標に応じて評価プロセスを調整するために必要です。
(v) サンプラーコードの設定
simple-evalsフレームワーク内でOllamaベースの言語モデルをサポートするために、カスタムラッパークラスを作成します。 OllamaSampler そしてそれを内に留めておく utils/samplers/ollama_sampler.py。サンプラーは、言語モデルのパフォーマンスをテストおよび評価する上で不可欠なコンポーネントです。
# utils/samplers/ollama_sampler.py ollama をインポートします。クラス OllamaSampler: def __init__(self, model_name=None, temperature=0): self.model_name = model_name self.temperature = temperature def __call__(self, prompt_messages): prompt_text = prompt_messages[-1]["content"] response = ollama.chat( model=self.model_name, messages=[{"role": "user", "content": prompt_text}], options={"temperature": self.temperature} ) response_content = response["message"]["content"] return response_content def _pack_message(self, content, role): return {"role": role, "content": content}
この文脈では、それは サンプラー (Samplifier) 指定されたプロンプトに基づいて言語モデルから出力を生成する Python クラス。このツールは、モデルから多様で代表的な応答が生成されることを保証するために不可欠です。
simple-evals のサンプラーは OpenAI や Claude などのプロバイダーのみをカバーしているため、Ollama と互換性のあるインターフェースを提供するサンプラー クラスが必要です。これにより、評価フレームワークとのシームレスな統合が保証されます。
起きる OllamaSampler GPQA の質問プロンプトを抽出し、指定された温度でフォームに送信し、プレーンテキストの応答を返します。温度は出力のランダム性を制御する重要なパラメータです。
含まれる方法 _pack_message 出力形式が simple-evals の評価スクリプトが期待するものと一致することを確認します。これにより、一貫性が確保され、分析が容易になります。
6. 評価スクリプトを作成する
次のコードは、ファイル内に評価実装を設定する方法を示しています。 main.pyカテゴリーの使用を含む GPQAEval GPQA ベンチマーク テストを実行するための simple-evals ライブラリから。
関数 run_eval() これは、Ollama を通じて大規模言語モデル (LLM) を GPQA などの標準に照らしてテストする、構成可能な評価ランタイム ツールです。この機能は、モデルのパフォーマンスを正確に評価するために必要です。
# main.py def run_eval(): start_time = time.time() # 設定ファイルをロード config = load_config("config/config.yaml") # Ollamaサンプラー(Ollamaチャットのラッパー)を初期化 ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperature=config["MODEL_TEMPERATURE"] ) # EVAL_BENCHMARKに基づいて使用する評価クラスを選択 eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> {eval_benchmark}評価を実行中") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # デフォルト1 "num_examples": config["EVAL_N_EXAMPLES"], # 設定20まで "variant": config["GPQA_VARIANT"], # GPQA-Diamondサブセット } else: raise ValueError( f"Unknown EVAL_BENCHMARK '{eval_benchmark}'." ) # 適切なevalをインスタンス化して実行します evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # サンプラーで評価を実行します end_time = time.time() elapsed_seconds = end_time - start_time minutes, seconds = divmod(elapsed_seconds, 60) # 合計所要時間を計算します # 返される結果は、SingleEvalResultと集計されたメトリックのリストを含むEvalResultです print(">>>> 全体の評価メトリック:", results.metrics) print(">>>> スコア:", results.score) print(f">>>> 合計実行時間: {int(minutes)} 分 {seconds:.2f} 秒") if __name__ == "__main__": # GPQA評価実行 run_eval()
この関数は、構成ファイルから設定を読み込み、simple-evals から適切な評価クラスを設定し、均一な評価プロセスを通じてモデルを実行します。ファイルに保存されます。 main.pyは、コマンドを使用して実行できます python main.py。これにより、一貫性があり繰り返し可能な評価プロセスが保証されます。
上記の手順に従うことで、DeepSeek-R1 蒸留モデルで GPQA-Diamond ベンチマークを正常にセットアップして実行できました。このプロセスにより、モデルの機能に関する貴重な洞察が得られます。
結論
この記事では、OllamaやOpenAIのsimple-evalsなどのツールを組み合わせて、DeepSeek-R1から抽出されたモデルを探索および評価する方法を、特に以下の点に焦点を当てて検討します。 大規模言語モデルの性能評価.
精製されたモデルは、GPQA-Diamond のような難しい推論ベンチマークでは、元の 671 億パラメータのモデルにまだ一致しない可能性があります。ただし、蒸留によって大規模言語モデル (LLM) の推論機能へのアクセスがどのように拡張できるかを示しています。 大規模言語モデルへのアクセスの改善 それはこの分野における大きな目標です。
複雑な博士レベルのタスクではパフォーマンスが低いにもかかわらず、これらの小さなバリアントは、それほど要求の厳しくないシナリオでは依然として適用可能であり、より幅広いデバイスでの効率的なローカル展開への道を開きます。これは、 大規模な言語モデルをローカルに展開する 効率的に。
コメントは締め切りました。