

インテリジェントな意思決定回路を用いた大規模言語モデル(LLM)の確実性の実現
不確実性はテクノロジーにおいて新しいものではありません。現代のシステムはすべて、数学的に証明された制御構造を使用して、不確実な入力と出力を克服しています。
AI エージェントの将来性は世界に大きな衝撃を与えました。エージェントは周囲の世界とやりとりしたり、記事を書いたり(この記事は除く)、ユーザーに代わってアクションを実行したり、一般的にあらゆるタスクの自動化の難しい部分を簡単かつアクセスしやすいものにしたりすることができます。
エージェントは、運用の最も難しい部分をターゲットにし、問題に迅速に対処します。速すぎる場合もあります – エージェントベースのプロセスで結果を決定するために人間が関与する必要がある場合、人間によるレビュー段階がプロセスのボトルネックになる可能性があります。
エージェントベースのプロセスの例としては、顧客からの電話の処理と分類が挙げられます。 99.95% の精度を持つエージェントでも、5 件の通話を聞くと 10,000 つのエラーが発生します。エージェントはそれを知っているにもかかわらず、あなたに伝えることができません。 どれ 5 件の通話のうち 10,000 件が誤分類されました。

「LLM を裁判官として利用する」手法は、各入力を別の LLM プロセスに入力して、その入力からの出力が正しいかどうかを評価する手法です。ただし、これは別の LLM プロセスであるため、不正確である可能性もあります。これら 2 つの確率的演算により、真陽性、偽陰性、真陰性、および偽陽性を含む混同マトリックスが作成されます。
つまり、LLM プロセスによって正しく分類されたエントリが、その判定者である LLM によって不正確であると判断される可能性があり、その逆も同様です。
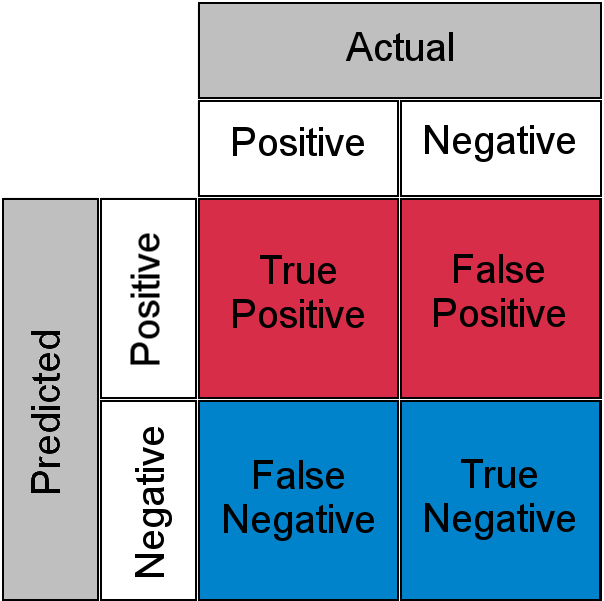
このため " 未知の既知の 「機密性の高いワークロードの場合、10,000万件の通話すべてを人間が確認して理解する必要があります。また同じボトルネックの問題に戻ってしまいます。」
エージェント駆動型プロセスに、より統計的な確実性をどのように組み込むことができるでしょうか?この記事では、エージェント駆動型プロセスの確実性を高めるシステムを構築し、任意の数のエージェントに一般化し、システムへの将来の投資を導くためのコスト関数を開発します。この記事で使用したコードは、私のリポジトリで公開しています。 AI決定回路.
AI意思決定回路
エラーの検出と修正は新しい概念ではありません。エラー訂正は、デジタルおよびアナログ電子工学などの分野では非常に重要です。量子コンピューティングの進歩も、エラー訂正および検出機能の拡張に依存します。これらのシステムからインスピレーションを得て、AI エージェントで同様のものを実装することができます。例えば、 人工知能アルゴリズム 通信システムにおけるエラー訂正技術の高度な利用。
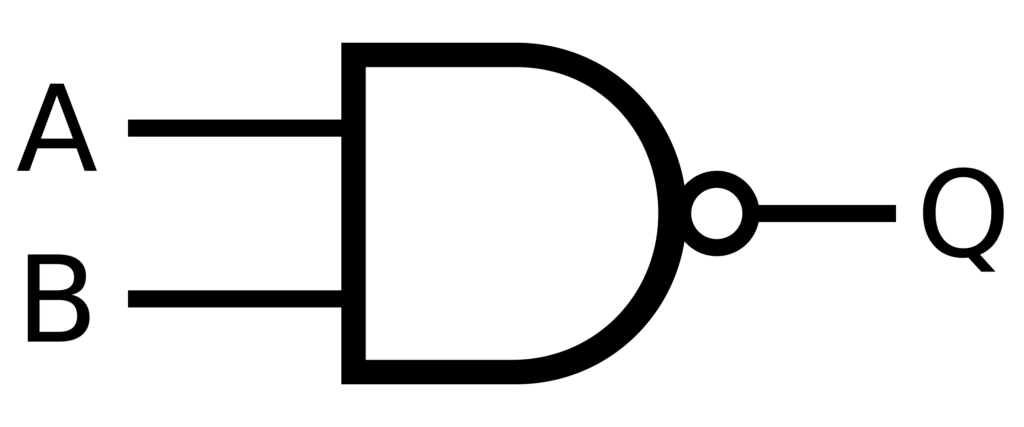
ブール論理では、NAND ゲートはあらゆる演算を実行できるため、計算の聖杯です。機能的に完全であり、NAND ゲートのみを使用してあらゆる論理演算を作成できます。この原理を AI システムに適用すると、エラー修正機能が組み込まれた堅牢な意思決定構造を作成できます。これにより、 ニューラルネットワーク 信頼性が高く、不完全なデータやノイズの多いデータも処理できます。
電子回路からインテリジェントな意思決定(AI)回路へ
電子回路が繰り返しと検証を使用して計算の信頼性を確保するのと同様に、インテリジェントな意思決定 (AI) 回路は、異なる視点を持つ複数のエージェントを使用して、より正確な結果を導き出すことができます。これらの回路は、情報理論とブール論理の原理を使用して構築できます。
- 冗長処理: 複数の AI エージェントが同じ入力を独立して処理します。これは、最新の CPU が冗長回路を使用してハードウェア エラーを検出するのと同様です。このプロセスにより、AI システムの信頼性が向上します。
- コンセンサスメカニズム: 決定出力は、フォールト トレラント エレクトロニクスの多数決論理ゲートと同様に、投票システムまたは加重平均を使用して結合されます。これらのメカニズムにより、最終決定がエージェント間の合意を反映することが保証されます。
- バリデータエージェント: 専門のAI監査人は、次のようなエラー検出コードと同様に動作して、出力の妥当性をチェックします。 パリティビット أو 巡回冗長検査(CRC検査)。これらのエージェントは、誤った決定を下す可能性を減らします。
- ヒューマン・イン・ザ・ループ統合: 生体認証システムが最終的な検証層として人間の監視を使用するのと同様に、意思決定プロセスの重要なポイントで戦略的な人間による検証を行います。これにより、重要な決定は人間による評価を受けることになります。
人工知能における意思決定回路の数学的基礎
これらのシステムの信頼性は、確率論を使用して定量的に判断できます。
一つの要因として、失敗の確率は、次のようなシステムに保存されているテストデータセット全体にわたって、時間の経過とともに観測される精度から生じます。 ラング・スミス.

90%の精度の要因の場合、失敗の確率は、 p_1، 1–0.9 それは0.1、つまり10%です。

2 つの独立した要素が同じ入力で失敗する確率は、両方の要素が正確である確率を掛け合わせたものです。
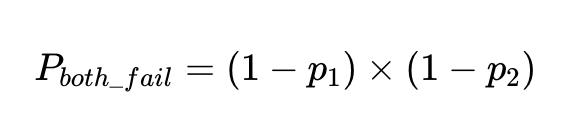
これらのクライアントでN回実行した場合、失敗の総数は
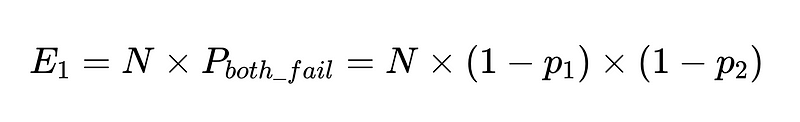
したがって、10,000% の精度で 90 人の独立したワーカー間で 100 回の実行が行われた場合、予想される失敗数は XNUMX です。
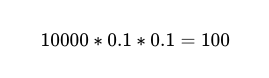
しかし、まだ分かりません。 どれ 10,000 件の電話のうち、100 件は実際の失敗です。
このアイデアの 4 つの拡張を組み合わせることで、特定の応答に信頼性を提供する、より堅牢なソリューションを提供できます。
- 基本的な分類器(上記の単純な解決)
- バックアップ(上記の簡単な解決策)
- スキーマチェッカー(例:解像度0.7)

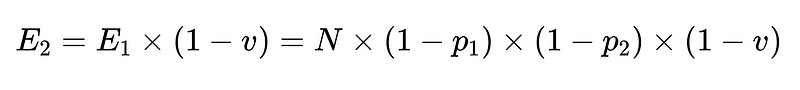
- 最後に、ネガティブバリデータ(例えばn = 精度0.6)
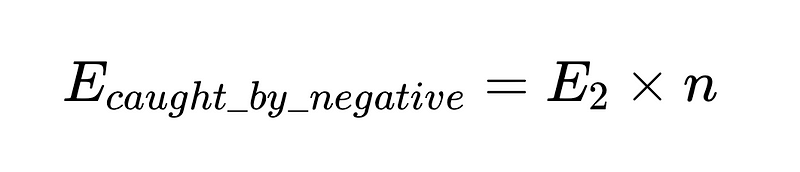
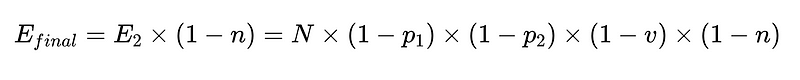
これをコードにすると(完全な倉庫)では、 Python 基本:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPESこれらの操作をロジックと組み合わせることで、 ブーリアン 簡単に言うと、それぞれの答えにおいて、同様の精度と信頼性が得られます。
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
意思決定ロジック:ステップバイステップの説明
ステップ1: 品質管理システムが機能しなくなった場合
if not validation_result:これは、「品質管理の専門家(監査人)が初期分析を拒否した場合は、それを信頼しないでください。」という意味です。システムは代わりにバックアップ意見を使用しようとします。これも検証に失敗した場合は、人間の専門家によるレビューのためにケースにフラグが付けられます。この手順により、不正確なデータに依存しないことが保証されます。
簡単に言うと、「最初の答えに何か問題があれば、バックアップの方法を試してみましょう。それでもまだ疑問がある場合は、人間の専門家に介入を依頼しましょう。」これにより、複雑なケースも正しく処理されるようになります。
ステップ2: 矛盾点に対処する
if negative_check == 'no' and primary_result['call_type'] is not None:このステップでは、特定のタイプの不一致をチェックします。「ネガティブ チェッカーはコール タイプがあってはならないことを示していますが、ファンダメンタル アナリストはとにかくタイプを見つけました。」
このような場合、システムはフォールバックアナリストに依存して損益分岐点に達します。
- バックアップアナリストが通話タイプがないことに同意した場合、通話は人間の要素に送信されます。
- バックアップアナリストがプライマリアナリストの意見に同意する場合は、その意見は受け入れられますが、信頼度は中程度となります。
- バックアップアナリストの通話タイプが異なる場合 ← 人間の要素に送信されます
これは、「ある専門家が『これは分類できない』と言い、別の専門家が『分類できる』と言った場合、決着をつける人や人間の審査員が必要だ」と言っているようなものです。このメカニズムは、通話タイプの分類を正確に行い、潜在的なエラーを減らすために必要です。
ステップ3:専門家が合意した場合
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:プライマリアナリストとバックアップアナリストの両方が独立して同じ結論に達した場合、システムはそれを「高い信頼性」とマークします。これが最良のシナリオです。この理想的な状況は、複数の分析が決定的に一貫している場合に発生します。
簡単に言えば、「2人の異なる専門家が異なる方法を使用して独立して同じ結論に達した場合、その結論が正しいと確信できます。」これは専門家の合意を表しており、正確性と信頼性の強力な指標となります。
ステップ4: デフォルト処理
いずれの特別な条件も当てはまらない場合、システムはデフォルトで、プライマリアナリストの「中程度」の信頼度の結果を使用します。主なアナリストが通話の種類を識別できない場合は、専門の人間アナリストによるレビューのためにケースにフラグを付けます。
エラーを減らすためのこのアプローチの重要性
このロジックは、次のような方法で強力なシステムの構築に貢献します。
- 誤検知の削減システムは複数の方法が一致した場合にのみ高い信頼性を与えるため、誤報が大幅に減少します。
- 矛盾を発見するシステムのさまざまな部分が異なる場合、信頼性が低下するか、問題が人間のレビュー担当者にエスカレートされ、潜在的な問題が見落とされないようにします。
- スマートエスカレーション人間のレビュー担当者は、専門知識が本当に必要なケースのみを確認するため、レビュー プロセスの効率が向上し、人的リソースのストレスが軽減されます。
- 信託指定結果にはシステムの信頼度レベルが含まれており、後続のプロセスでは、高信頼度の結果と中信頼度の結果を別々に扱うことができるため、情報に基づいた意思決定を行う上で重要です。
このアプローチは、電子機器が冗長回路と投票メカニズムを使用してエラーによるシステム障害を防ぐ方法に似ています。 AI システムでは、このような思慮深い統合ロジックにより、最も価値を付加できる部分のみに人間のレビュー担当者を効率的に活用しながら、エラー率を大幅に削減できます。これにより、リソースが最適化され、同時にエラーが削減され、より信頼性が高く正確なシステムが実現します。
例
2015年にフィラデルフィア市水道局は カテゴリ別の顧客通話統計。 顧客からの電話を理解することは、エージェントが扱う非常に一般的なプロセスです。人間がすべての顧客との電話通話を聞く代わりに、エージェントはより迅速に通話を聞いて情報を抽出し、通話を分類してさらにデータ分析を行うことができます。水管理にとって、これは重要です。重大な問題が早く特定されればされるほど、それらの問題も早く解決できるからです。
経験を積むことができます。私は大規模言語モデル (LLM) を使用して、「次のクラスが与えられた場合、その電話通話の短縮版を生成してください」という質問で、問題の電話通話の偽のトランスクリプトを生成しました。完全なファイルを含む例をいくつか示します。 ここで:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}さて、大規模な言語モデルを審査員として用いた、より伝統的な評価で実験を設定することができます(完全な実装はこちら):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_typeテキストのみを大規模言語モデル (LLM) に渡すことで、返される抽出されたクラスから実際のクラス知識を分離して比較することができます。
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return resultClaude 3.7 Sonnet (この記事の執筆時点での最新モデル) を使用して合成データセット全体でこれを実行すると、91% の通話が正確に分類され、非常に高いパフォーマンスが得られます。
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}これらが実際の通話であり、そのカテゴリについて事前の知識がなかったとしても、誤分類された 100 件の通話を見つけるには 9 件の通話すべてを確認する必要があります。
上記の強力な意思決定回路を適用することで、同様の精度の結果が得られます。 信頼 それらの答えの中で。この場合、全体的な精度は 87% ですが、信頼性の高い回答の精度は 92.5% です。
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}信頼性の高い回答には 100% の精度が必要なので、まだやるべき作業が残っています。このアプローチによって、私たちは 理由 信頼性の高い回答の不正確さ。この場合、主張が弱く、検証機能が単純であるため、すべての問題を把握できず、分類エラーが発生します。これらの機能は、繰り返し改善することで、信頼性の高い回答で 100% の精度を達成できます。
フィルタリング システムを改善し、結果の信頼性を高めました。
現在のシステムでは、主アナリストとバックアップアナリストが一致した場合、回答は「高い信頼性」として分類されます。より高い精度を達成するには、「高い信頼性」と見なされるものをより厳選する必要があります。
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}追加の資格基準を加えると、「信頼性の高い」結果の数は減りますが、精度は高まります。このフィルタリング システムの改善は、エラーを削減し、高品質と分類されたデータの信頼性を高めることを目的としています。
追加の検証技術:分析の精度の向上
データの検証と分析プロセスを強化するためのその他のアイデアを次に示します。
三次分析装置3 番目の独立した分析方法を追加します。この方法は、検証の追加レイヤーとして機能し、2 つの異なる分析方法の結果を 3 番目の方法の結果と比較することで、精度を高め、エラーの可能性を減らします。
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:履歴パターンマッチング:結果を歴史的に正しい結果と比較します (ベクトル検索を考えてください)。この手法では、信頼できる履歴データを参照として使用し、現在の結果と比較して逸脱や矛盾を特定します。これは分析のための一種の「メモリ」と考えることができ、異常や予期しない状況の検出に役立ちます。
if similarity_to_known_correct_cases(primary_result) > 0.95:敵対的テスト入力に小さな変化を適用し、分類が安定しているかどうかを確認します。この方法は、データに小さな変更を加えることで、分類システムの堅牢性と堅牢性をテストすることを目的としています。システムがこれらの変更に対して非常に敏感な場合、潜在的な弱点や偏りが示される可能性があります。
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
LLM抽出システムにおける人間の介入の一般式
- N = 実行回数の合計(この例では 10,000)
- p_1 = 基本パーサーの精度(この例では 0.8)
- p_2 = フォールバックパーサーの精度(この例では 0.8)
- v = スキーマ検証の有効性(この例では 0.7)
- n = ネガティブチェッカーの有効性(この例では 0.6)
- H = 必要な人的介入の回数
- E_final = 最終的な未検出エラー
- m = 独立監査人の数
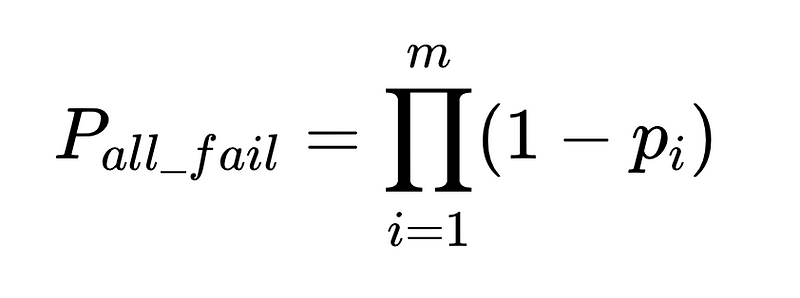
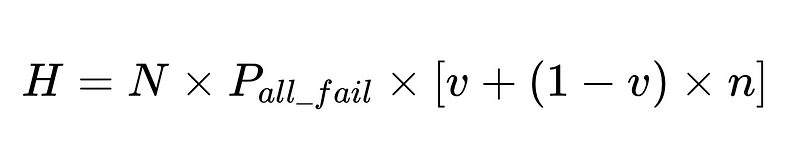
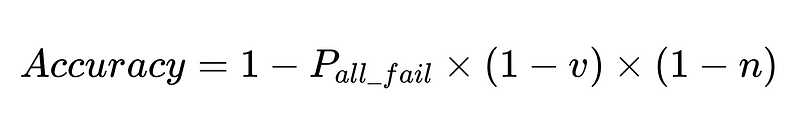
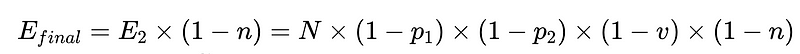
最適なシステム設計
この式は、自然言語処理 (NLP) システムの精度に関する重要な洞察を明らかにします。
- パーサーを追加するとオーバーヘッドが削減されますが、全体的な精度が向上します。
- システムの精度は以下によって制限されます:
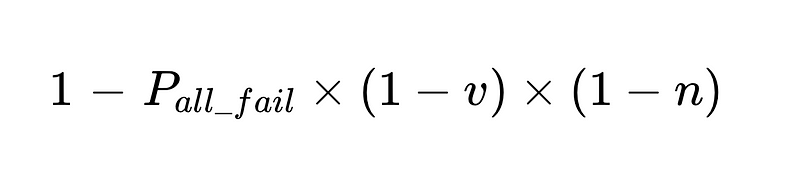
- 人間の介入は比例する 直接 合計 N 回実行します。
例えば:
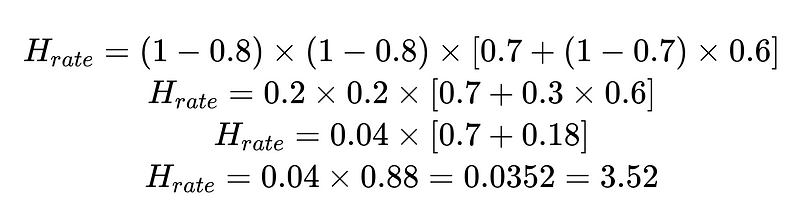
計算された人間の介入率 (H_rate) を使用して、ソリューションの有効性をリアルタイムで追跡できます。人間の介入率が 3.5% を超え始めると、システムが機能しなくなっていることがわかります。人間の介入率が一貫して 3.5% 未満に減少した場合、最適化が期待どおりに機能していることがわかります。
コスト関数
システムの改善に役立つコスト関数を作成することもできます。コスト関数は、システムの財務パフォーマンスを評価し、改善の可能性のある領域を特定するための強力な分析ツールです。
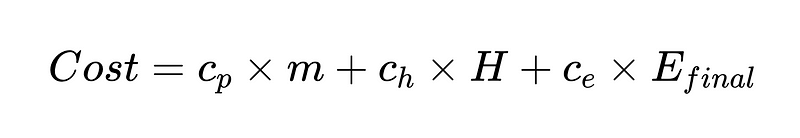
どこ:
- c_p = パーサーあたりの実行コスト(この例では 0.10 ドル)
- m = パーサーが実行される回数(この例では 2 * N)
- H = 人間の介入を必要とするケースの数(例では 352 件)
- c_h = 200 回の人間介入にかかるコスト (例: 4 時間で 50 ドル、XNUMX 時間あたり XNUMX ドル)
- c_e = 検出されないエラー1000件のコスト(例:XNUMXドル)
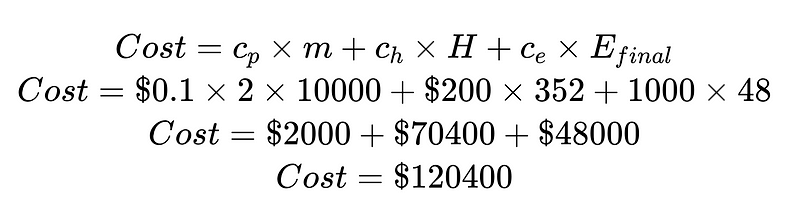
コストを人的介入のコストと未検出エラーのコストで割ることで、システム全体を改善できます。この例では、人的介入のコスト(70,400ドル)が望ましくなく高額であれば、信頼性の高い結果の向上に注力できます。一方、未検出エラーのコスト(48,000ドル)が望ましくなく高額であれば、Plus構文解析ツールを導入して未検出エラー率を低減できます。
もちろん、コスト関数は、それが説明する状況を改善する方法を探る方法として最も役立ちます。
上記のシナリオでは、検出されないエラーの数E_finalを50%削減するために、
- p1とp2 = 0.8、
- v = 0.7 かつ
- N = 0.6
3つの選択肢があります:
- 50%の精度を持つ新しい文法パーサーを追加し、セカンダリパーサーとして組み込みます。ただし、これにはトレードオフが伴うことに注意してください。Plus文法パーサーの実行コストと人的介入コストが増加します。
- 既存の文法パーサーをそれぞれ 10% 改善します。これらの構文解析ツールによって実行されるタスクの難しさにより、これが可能になる場合と不可能になる場合があります。
- 監査プロセスを 15% 改善します。繰り返しますが、これによって人間の介入によるコストが増加します。
AI信頼の未来:極限の精度による信頼の構築
AI システムがビジネスや社会の重要な側面にますます統合されるようになるにつれて、特に重要なアプリケーションでは最適な精度の追求がますます重要になります。 AI の意思決定にこれらの回路にヒントを得たアプローチを採用することで、効率的に拡張できるだけでなく、一貫性と信頼性の高いパフォーマンスからのみ得られる深い信頼を得られるシステムを構築できます。将来は、より強力な個々のモデルにあるのではなく、複数の視点と戦略的な人間の監視を組み合わせた、慎重に設計されたシステムにあります。
デジタル電子機器が信頼性の低い部品から進化し、最も重要なデータを預けられる信頼できるコンピューターを生み出したのと同じように、AI システムも今や同じような道を歩んでいます。この記事で説明するフレームワークは、最終的にはミッションクリティカルな AI の標準アーキテクチャとなるものの青写真であり、信頼性を約束するだけでなく、それを数学的に保証するシステムです。問題は、ほぼ完璧な精度で AI システムを構築できるかどうかではなく、これらの原則を最も重要なアプリケーション全体にどれだけ迅速に実装できるかです。
コメントは締め切りました。