

過去 2 年間のスマートフォン業界で最も目立った(そして率直に言って最も退屈な)トレンドの 1 つは、AI エクスペリエンスに関する絶え間ない話題です。特にシリコン企業は、自社の最新モバイル プロセッサがビデオ作成などのデバイス上での AI 操作を可能にするとよく自慢します。
完全にではありませんが、すでにそこにいます。スマートフォン ユーザーにとって当たり外れがある AI トリックをめぐる大騒ぎの中で、新しいプロセッサや進化し続けるチャットボットの派手な展示を超える議論はほとんど行われていません。
Google Pixel 8 に Gemini Nano が搭載されていないことが注目を集めて初めて、モバイル デバイスの AI にとって RAM 容量が極めて重要であることが一般の人々に知られるようになりました。 Apple はまた、Apple Intelligence を少なくとも 8GB の RAM を搭載したデバイスに限定し続けることもすぐに明らかにしました。この決定は、AI モデルを効率的に実行する上での RAM の重要性を反映しています。
しかし、「AIフォン」のイメージはメモリ容量だけではありません。携帯電話が AI を活用したタスクをどれだけうまく実行できるかは、目に見えない RAM の最適化とストレージにも左右されます。いいえ、私は容量についてだけ話しているのではありません。
メモリの革新が AI フォンにも導入されます。

Digital Trends は、メモリおよびストレージ ソリューションの世界的リーダーである Micron と話し合い、スマートフォン上の AI 操作における RAM とストレージの役割を分析しました。次に高級スマートフォンを購入するときは、Micron の進歩に注目するべきです。
アイダホ州に本社を置く同社の最新製品には、主力スマートフォン向けの G9 NAND モバイル UFS 4.1 ストレージと 1γ (1-ガンマ) LPDDR5X RAM モジュールが含まれています。では、これらのメモリソリューションは、容量を増やす以外に、スマートフォンの AI をどのように進化させるのでしょうか?
まずは、G9 の NAND UFS 4.1 ストレージ ソリューションから始めましょう。 主な約束は、経済的な電力消費、レイテンシの削減、および高帯域幅です。。 UFS 4.1 規格では、ピーク時のシーケンシャル読み取りおよび書き込み速度が 4100MB/秒に達し、UFS 15 世代に比べて 4.0% 向上するとともに、レイテンシの数値も削減されます。
もう 2 つの重要な利点は、Micron の次世代ポータブル ストレージ ユニットが最大 XNUMX TB の容量で利用できることです。さらに、マイクロンはサイズを縮小することに成功し、折りたたみ式携帯電話や次世代のスリム携帯電話に最適なソリューションとなっています。 サムスンギャラクシーエッジS25.
RAM の進歩に移ると、Micron は 1γ LPDDR5X RAM モジュールと呼ばれるものを開発しました。最高速度は 9200 MT/s で、サイズが縮小されたためトランジスタの搭載量が 30% 増加し、同時に消費電力も 20% 削減されます。 Micron はすでに、Samsung Galaxy S1 シリーズのスマートフォンに搭載されている、やや遅い 1β (25-beta) RAM ソリューションを導入しています。
ストレージと人工知能の相互作用
マイクロンのモバイル事業部門の製品マーケティングディレクターであるベン・リベラ氏は、モバイルデバイスでのAI操作を高速化するために、マイクロンが最新のストレージソリューションに4つの重要な改良を導入したと説明した。これらの改善には、Zoned UFS、データ デフラグ、Pinned WriteBooster、Intelligent Latency Tracker が含まれます。
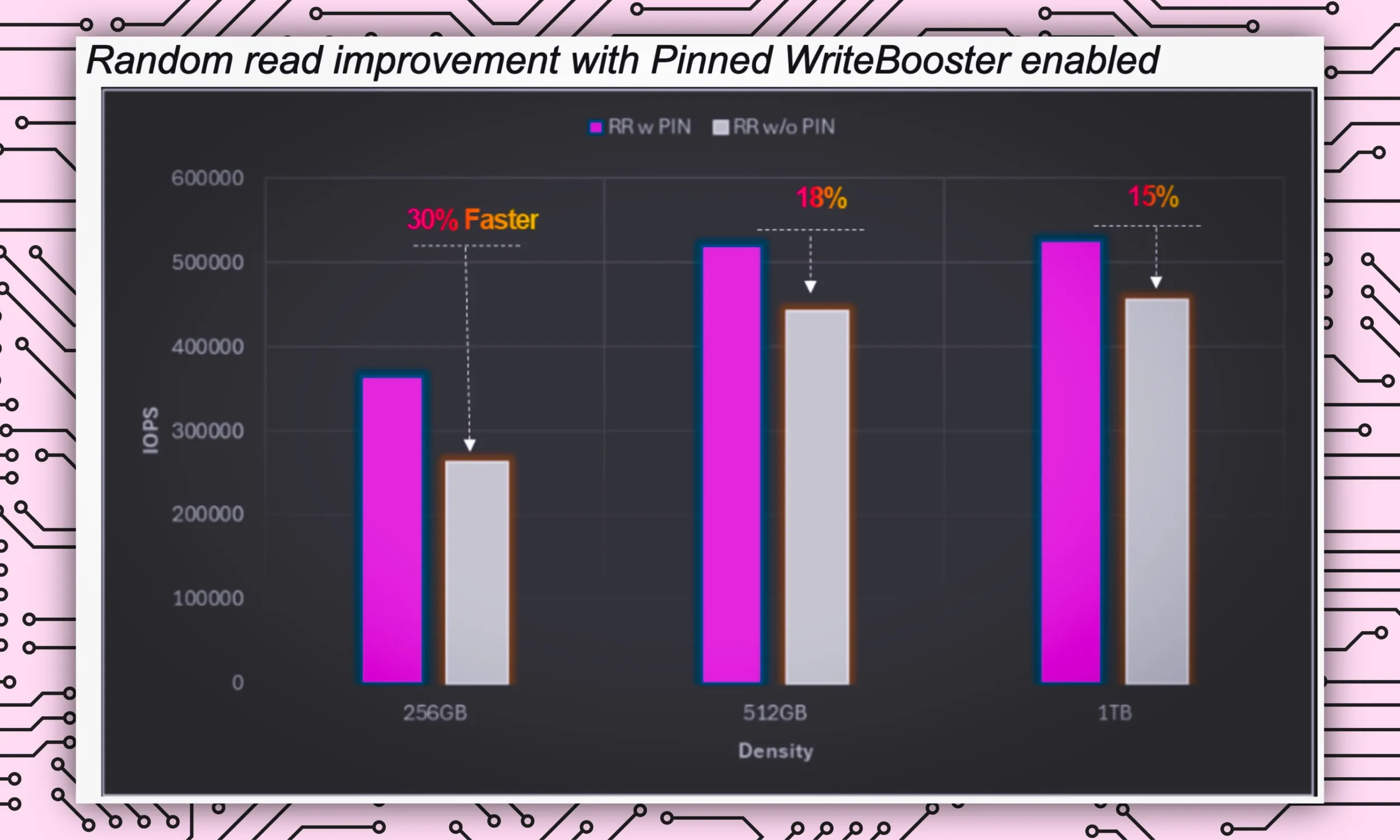
「この機能により、プロセッサまたはホストは、スマートフォンで最も頻繁に使用されるデータを識別して、WriteBoosterバッファ(キャッシュに類似)と呼ばれるストレージデバイスの領域に分離、つまり『ピン留め』し、高速で即時のアクセスが可能になります」とリベラ氏はPinned WriteBooster機能について説明しています。
Google Gemini や ChatGPT など、デバイス上でタスクを実行しようとするすべての AI モデルには、モバイル デバイス上にローカルに保存される独自の命令ファイル セットが必要です。例えば、 Apple Intelligence 最大7GBのストレージ容量 すべての操作について。
タスクを実行するには、通話や他の重要なアプリケーションとのやり取りなど、他の重要なタスクを処理するためのスペースが必要になるため、AI スタック全体を RAM に委任することはできません。 Micron ストレージの制限に対処するために、必要な AI 重みのみをストレージから RAM にロードするメモリ マップが作成されます。
リソースが制限されるとき、必要なのはデータのスワップと読み取りの高速化です。これにより、他の重要なタスクの速度に影響を与えることなく、AI タスクが実行されるようになります。 Pinned WriteBooster のおかげで、このデータ交換は 30% 高速化され、AI タスクが遅延なく処理されるようになります。
必要だとすると 分析用にPDFファイルを抽出するGemini。高速メモリスワッピングにより、必要な AI 重みがストレージから RAM にすばやく転送されます。
次に、Data Defrag があります。これを机やクローゼットの整理箱として考えれば、物がさまざまなカテゴリにきちんと分類され、それぞれのキャビネットに配置され、簡単に見つけられるようになります。
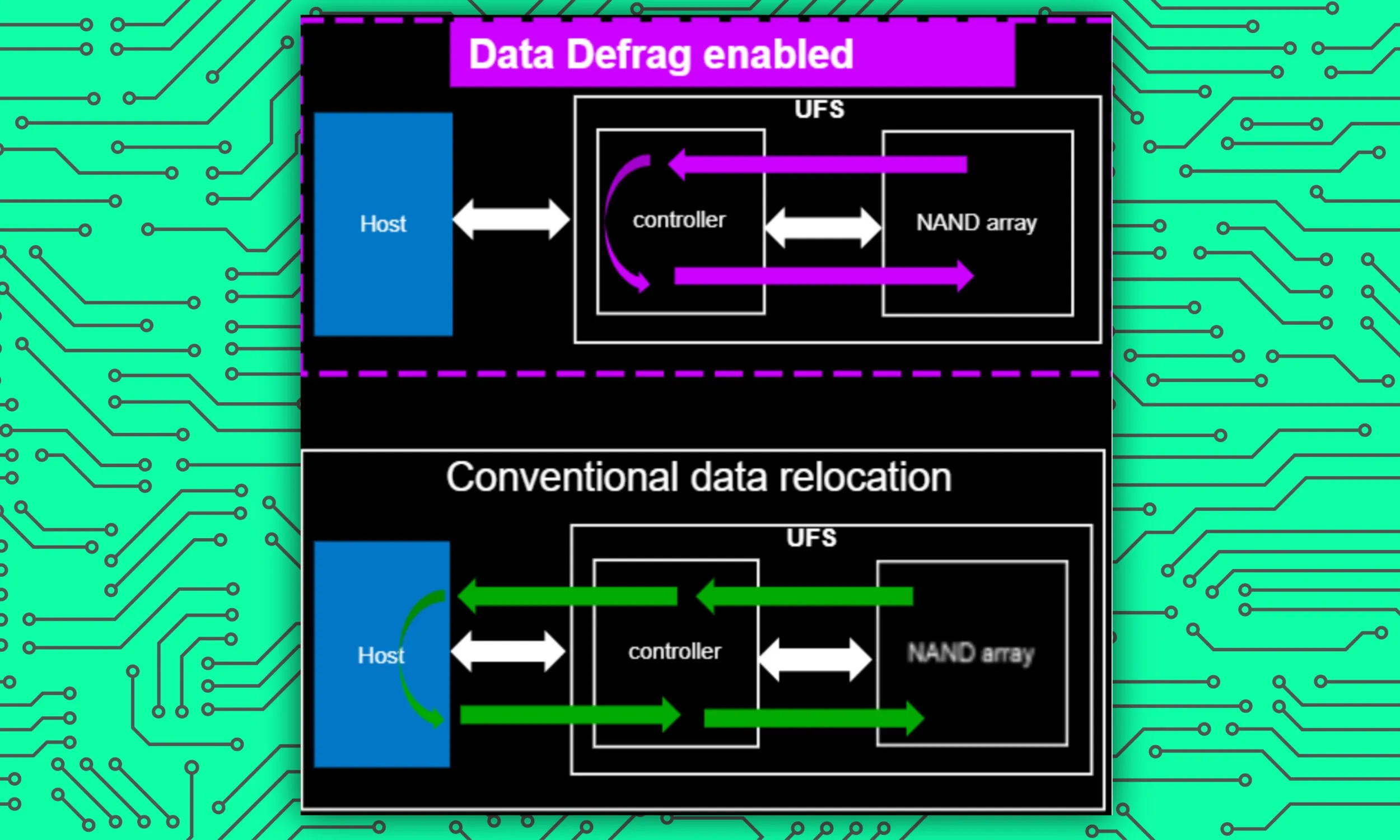
スマートフォンの場合、長期間の使用で大量のデータが保存されますが、通常はある程度ランダムな方法で保存されます。その結果、オンボードシステムが特定の種類のファイルにアクセスする必要がある場合、すべてのファイルを見つけるのが難しくなり、動作が遅くなります。
Rivera 氏によると、Data Defrag はデータの整理された保存に役立つだけでなく、ストレージ デバイスがデバイスのコントローラーと対話する方法も変更します。したがって、それは データ読み取り速度を驚異の60%向上AI タスクを含む、あらゆる種類のユーザーとデバイスのインタラクションを自然に加速します。
「この機能は、テキストプロンプトから画像を生成するために使用されるような生成AIモデルがストレージからメモリに呼び出される場合など、AI機能を高速化するのに役立ち、ストレージからメモリへのデータの読み取りが高速化されます」とマイクロンの担当者はDigital Trendsに語った。
Intelligence Latency Tracker は、基本的に、携帯電話の通常の速度を低下させる可能性のある遅延イベントと要因を監視するもう 1 つの機能です。その後、エラーを修正し、携帯電話のパフォーマンスを向上させて、通常のタスクだけでなく AI タスクでも速度低下が発生しないようにするのに役立ちます。
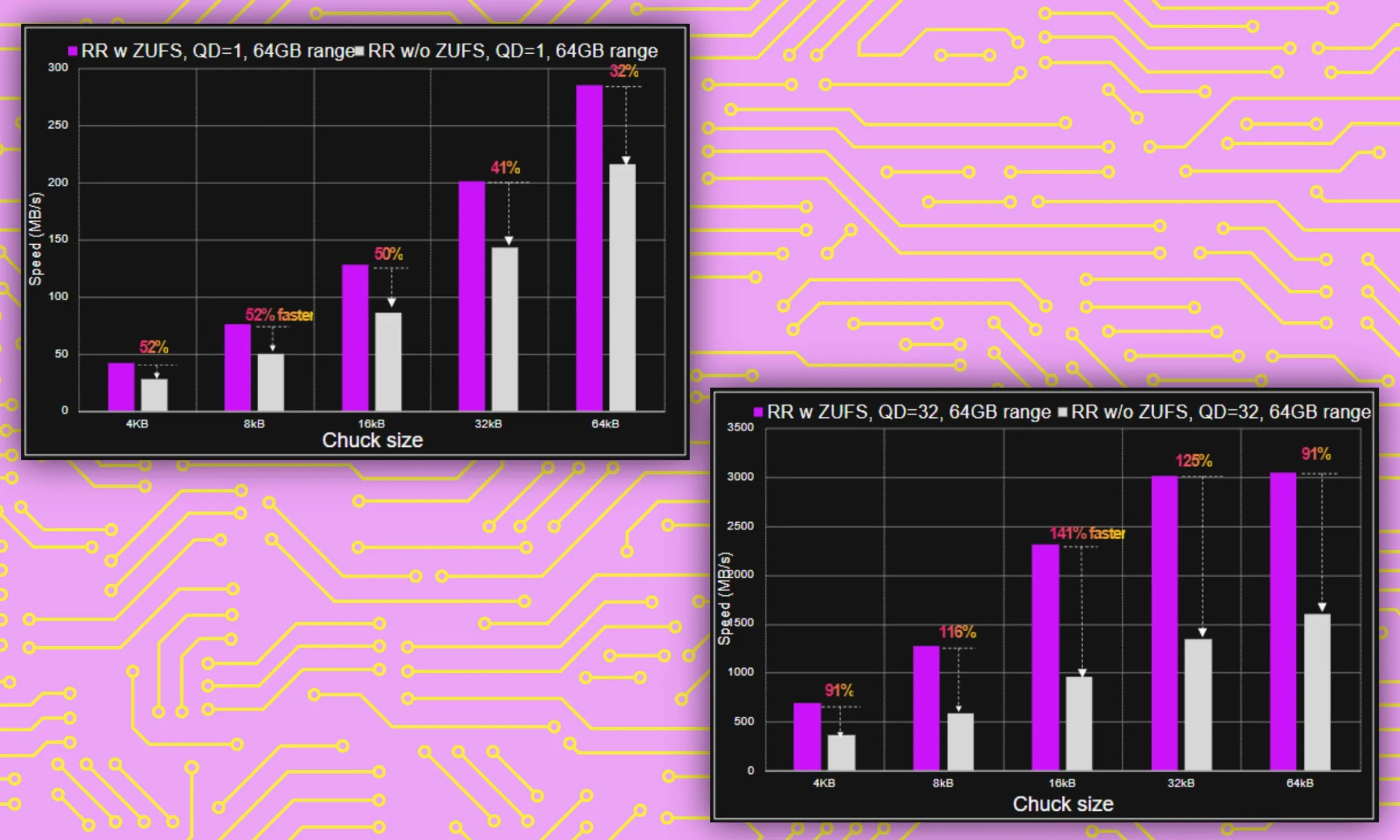
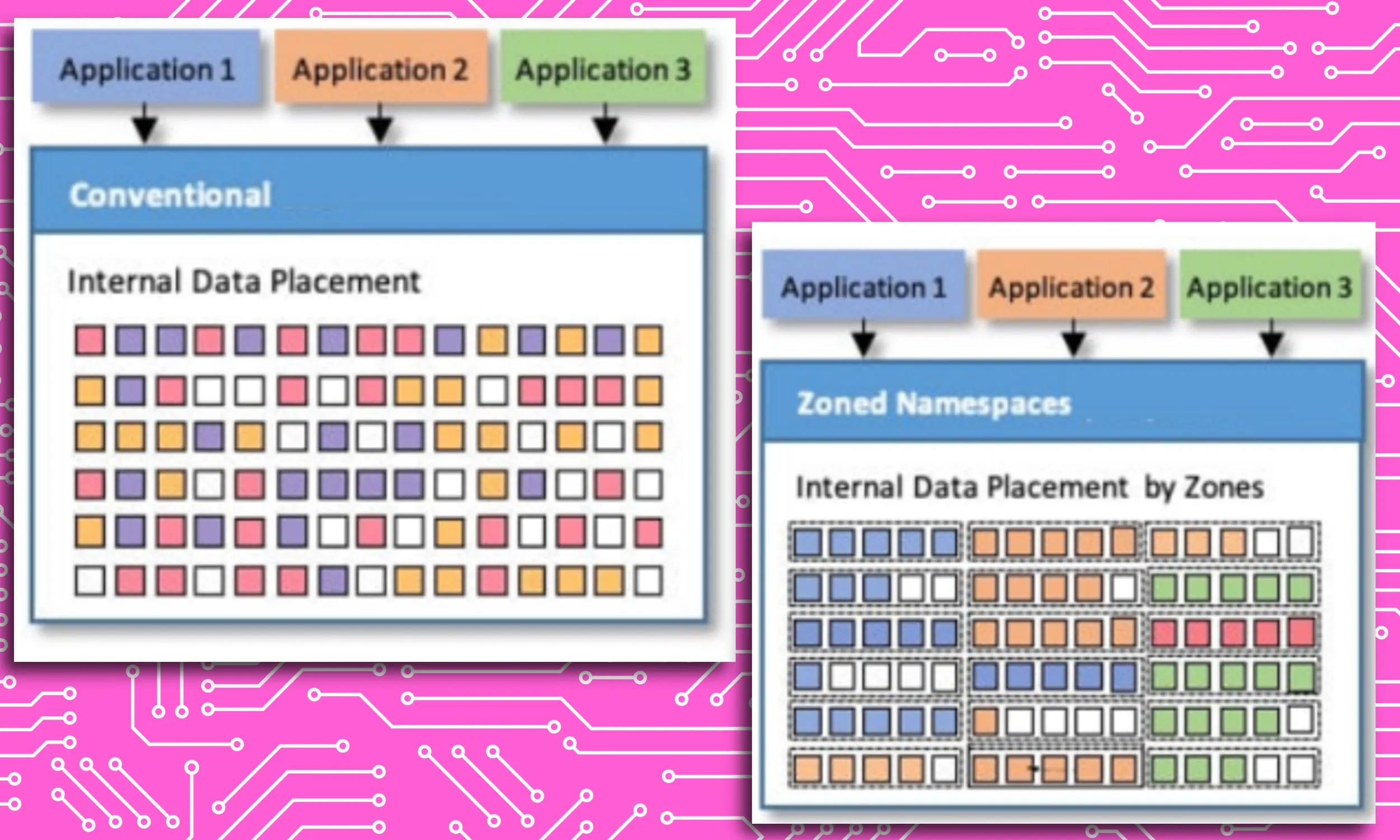
最後のストレージの改善は、Zoned UFS です。このシステムにより、同様の入力/出力特性を持つデータが整理された方法で保存されることが保証されます。これは、すべてのフォルダーとディレクトリを検索して時間を無駄にするのではなく、システムが必要なファイルを見つけやすくするため、非常に重要です。
「マイクロンのZUFS機能はデータの整理に役立ち、システムがタスクの特定のデータを探す必要があるときに、プロセスがより高速かつスムーズになります」とリベラ氏は語った。
RAMオーバーフロー
AI ワークフローに関しては、一定量の RAM が必要です。容量が多ければ多いほど良いです。 Apple は Apple Intelligence スイートのベースラインを 8GB に設定していますが、Android エコシステムのプレーヤーは安全なデフォルトとして 12GB に移行しています。なぜ?
「AI エクスペリエンスは、大量のデータと大量のエネルギーを必要とします」とリベラ氏は説明します。 「したがって、AIの実現には、メモリとストレージが低レイテンシと高パフォーマンスを最大限のエネルギー効率で実現する必要があります。」
Micron は、スマートフォン向けの次世代 5γ (1 ガンマ) LPDDR1X DRAM ソリューションにより、メモリ モジュールの動作電圧を低減することに成功しました。次に、ローカルパフォーマンスという非常に重要な問題があります。リベラ氏によると、新しいメモリモジュールは最大9.6ギガビット/秒の速度で動作し、優れたAIパフォーマンスを保証するという。
マイクロン社は、極端紫外線(EUV)リソグラフィー工程の改良により、速度の向上だけでなく、エネルギー効率も20%向上する見通しがついたと述べている。
よりパーソナライズされた AI エクスペリエンスへの道?
Micron のスマートフォン向け次世代 RAM およびストレージ ソリューションは、AI パフォーマンスの向上だけでなく、日常的なスマートフォン タスクの全体的な高速化も目標としています。 G9の改良されたNANDモバイルUFS 4.1ストレージと1γ(1ガンマ)LPDDR5X RAMがオフラインAIプロセッサの速度も向上させるのではないかと考えました。
スマートフォンメーカーや AI ラボは、ローカル AI 処理への移行を進めています。つまり、クエリをクラウド サーバーに送信してそこでプロセスが処理され、その結果がインターネット接続を使用して携帯電話に送信されるのではなく、ワークフロー全体が携帯電話上でローカルに実行されます。

通話や音声メモの書き起こしから複雑な調査資料の PDF への処理まで、すべてがスマートフォン上で行われ、個人データがデバイスから外に出ることはありません。これはより安全で高速なアプローチですが、同時に強力なシステム リソースが必要になります。より高速で効率的なメモリ モジュールは、これらの必須要件の 1 つです。
Micron の次世代ソリューションは、ローカルでの AI の解決に役立ちますか?彼女ならできるよ。実際、Google の Veo モデルを使用してビデオを作成するなど、強力なコンピューティング サーバーを必要とするクラウド接続を必要とするプロセスも高速化されます。
「デバイス上で直接実行されるネイティブ AI アプリケーションは、ストレージ デバイスからユーザー データを読み取るだけでなく、デバイス上で AI 推論も実行するため、トラフィックが最も多くなります」とリベラ氏は述べています。 「この場合、当社の機能は両方のデータフローを最適化するのに役立ちます。」
では、Micron の最新ソリューションを搭載したスマートフォンが店頭に並ぶのはいつ頃になるのでしょうか?リベラ氏は、すべての主要スマートフォンメーカーがマイクロンの次世代RAMおよびストレージモジュールを採用するだろうと述べている。市場へのアクセスという点では、「2025年後半または2026年初頭に発売される主なモデル」が購入の際のレーダーに載せるべきです。
コメントは締め切りました。