

特徴選択とは、与えられた特徴セットから最適な特徴のサブセットを選択するプロセスです。最適なサブセットとは、特定のタスクにおけるモデルのパフォーマンスを最大化するサブセットです。
特徴の識別は手動で行うこともできますが、 フィルターメソッドまたはラッパーメソッド。これらの方法では、固定メトリックの値に基づいて機能が反復的に追加または削除されます。この値によって、予測を行う際に機能がどの程度重要かが決定されます。指標は情報ゲイン、分散、またはカイ二乗統計値であり、アルゴリズムは指標の固定しきい値を考慮して特徴を受け入れるか拒否するかを決定します。これらの方法はモデルトレーニングフェーズの一部ではなく、その前に実行されることに注意してください。
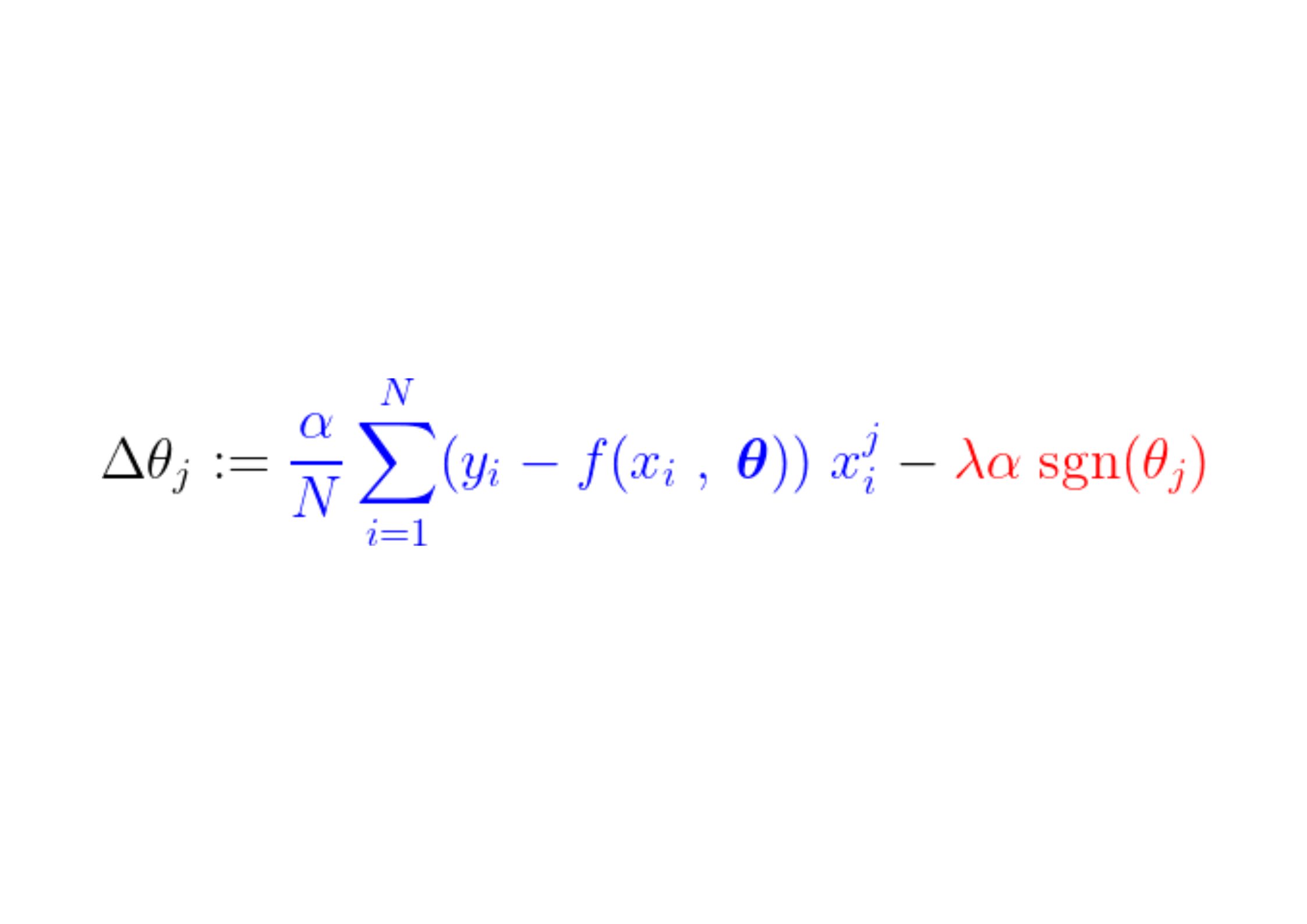
起きる 埋め込みメソッド 事前定義された選択基準を使用せずに暗黙的に特徴を選択し、トレーニング データ自体から特徴を抽出します。重要な特徴を識別するこのプロセスは、モデルのトレーニング フェーズの一部です。モデルは特徴を識別し、同時に関連する予測を行うことを学習します。以降のセクションでは、L1 正則化と機械学習モデルの改善におけるその役割に焦点を当て、この重要な特徴選択プロセスにおける正則化の役割について説明します。
正規化とモデルの複雑さ:パフォーマンスを向上させるための高度な戦略
正則化とは、過剰適合を回避し、タスクの一般化を実現するために、モデルの複雑さをペナルティするプロセスです。
ここで、モデルの複雑さは、トレーニング データ内のパターンに適応する能力に似ています。 'の単純な多項式モデルを仮定すると、x「ある程度」d「スコアが高いほど」d多項式の場合、モデルは観測データ内のパターンを捉える柔軟性が高くなります。この柔軟性の向上により、モデルは実際のパターンを学習するのではなく、トレーニング データを記憶するようになり、新しいデータへの一般化能力が低下する可能性があります。
過剰適合と不足適合
次数を持つ多項式モデルを当てはめようとする場合 d = 2 ノイズの含まれる 3 次多項式から抽出されたトレーニング サンプル セットでは、モデルはサンプリング分布を適切に取得できません。このモデルには、 柔軟性 أو 複雑 3 次以上の多項式によって生成されたデータをモデリングするために必要です。このモデルは 不適合 トレーニングデータについて。アンダーロードは、モデルが単純すぎて、データ内の基本的なパターンをキャプチャできないことを示します。
同じ例を使って、次数のあるモデルがあると仮定します。 d = 6。複雑さが増したため、モデルはデータを生成するために使用された元の 3 次多項式を簡単に推定できるようになります (たとえば、指数が 0 を超えるすべての項の係数を XNUMX に設定します)。トレーニング プロセスが時間内に完了しない場合、モデルは追加の柔軟性を引き続き使用してエラーをさらに削減し、ノイズの多いサンプルのキャプチャも開始します。これにより、トレーニングエラーは大幅に減少しますが、モデルは 過剰適合 トレーニングデータについて。ノイズは現実世界の設定(またはテスト段階)で変化し、予測に基づく知識は混乱をきたし、結果としてテスト エラーが増大します。オーバーロードとは、モデルが複雑になりすぎて、実際の信号ではなくノイズを学習することを意味します。
モデルの最適な複雑さをどのように決定するのでしょうか?
実際の現場では、データ生成プロセスやデータの実際の分布について理解が不十分であったり、まったく理解できていないことがよくあります。過学習や過学習が起こらないよう、適切な複雑さを持つ最適なモデルを見つけることは、大きな課題です。これには、モデルのパフォーマンスを評価し、精度と一般性の間の最適なバランスを実現する適切な複雑さを決定するための効果的な方法を使用する必要があります。適切な評価指標とクロス検証などの手法を使用することで、専門家は未知のデータに対して最適なパフォーマンスを発揮するモデルを特定し、過剰適合や不足適合の問題を回避できます。
考えられる手法の 1 つは、十分に堅牢なモデルから始めて、特徴選択によって複雑さを軽減することです。機能が少ないほど、モデルの複雑さは軽減されます。
前のセクションで説明したように、特徴選択は明示的 (フィルタリング方法、畳み込み方法) または暗黙的に行うことができます。ターゲット変数の値を決定する上でそれほど重要ではない冗長な特徴は、モデルがそれらの特徴の中で相関のないパターンを学習することを避けるために削除する必要があります。正規化も同様のタスクを実行します。では、正規化と特徴選択は、最適なモデル複雑性という共通目標の達成にどのように関係するのでしょうか?機械学習モデルの複雑さを軽減することは、パフォーマンスを向上させ、過剰適合を回避するために重要であり、これは正規化と特徴選択の両方が重点を置いていることです。
特徴決定要因としてのL1正則化
多項式モデルを続けて、これを関数fとして表現します。入力は x、および取引 θ 学位 d،
![]()
多項式モデルの場合、入力の各べき乗は次のように考えることができる。 x_i 利点として、次の形式のベクトルを形成します。
![]()
また、目的関数を定義し、それを最小化することで最適なパラメータを導きます。 θ* この用語には以下が含まれます。 正則化 (規制)モデルの複雑さを罰する。
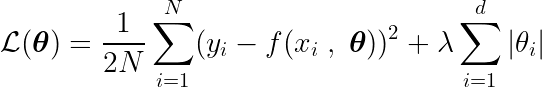
この関数の最小値を見つけるには、すべての臨界点、つまり導関数がゼロまたは未定義である点を分析する必要があります。
偏微分は、パラメータの1つに関して次のように表すことができます。 θj、 次のように:
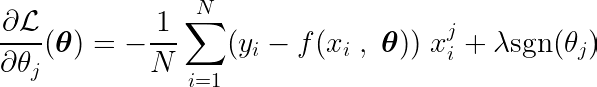
関数が定義されている場所 SGN 次のように:
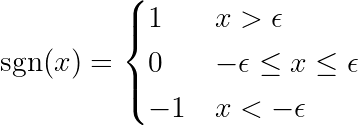
通知絶対関数の導関数は、上で定義した符号関数 (sgn) とは異なります。元の導関数は x = 0 では定義されていません。定義を拡張して、 x = 0 での変曲点を削除し、関数をその範囲全体で微分可能にします。さらに、機械学習 (ML) フレームワークは、基礎となる計算に絶対関数が含まれる場合にこれらの拡張機能を使用します。これをチェックしてください! リンク PyTorch フォーラムにて。
目的関数の偏微分を単一の係数について計算することにより θjをゼロとすれば、最適値と θj 予測、目標、特徴付き。
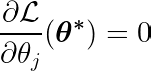
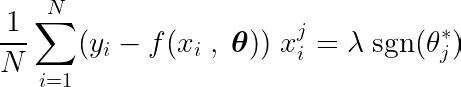
上の式を検証してみましょう。入力とターゲットが平均値を中心に配置されている(つまり、データが前処理段階で標準化されている)と仮定すると、左側の項(LHS)は実質的に 英語 特徴番号 j と、期待値と目標値の差の間。
2 つの変数間の統計的共分散は、1 つの変数が 2 番目の変数の値に与える影響の大きさを決定します (逆も同様)。
右側の sign 関数は、左側のバリエーションが 1 つの値のみを想定するように強制します (sign 関数は -0、1、XNUMX のみを返すため)。機能が j 不要であり予測に影響を与えない場合、分散はゼロに近くなり、対応する係数は θj* ゼロ。この結果、モデルからフィーチャが削除されます。このプロセスは複雑さを軽減し、モデルのパフォーマンスを向上させるのに役立ちます。
標識の機能を水によって刻まれた溝として想像してください。渓谷(つまり川床)へは歩いて入ることができますが、そこから出るには巨大な障害物や急流に遭遇することになります。 L1 正則化は、損失関数の勾配に似た「しきい値」効果を生み出します。勾配は障壁を破るほど強力であるか、またはゼロになって最終的に係数値がゼロになる必要があります。
より現実的な例として、ノイズが追加された直線(2 因子パラメータ化)から得られたサンプルを含むデータセットを検討します。最適なモデルは 2 つ以上のパラメータを持つべきではありません。そうでないと、データ内のノイズに過剰適合してしまいます (多項式の自由度/パワーが追加されます)。多項式モデルの高次係数を変更しても、ターゲットとモデル予測の差には影響せず、特徴との分散が減少します。
トレーニング プロセス中に、損失関数の勾配に固定ステップが加算/減算されます。損失関数の勾配(MSE – 平均二乗誤差)が定数ステップよりも小さい場合、係数は最終的に 0 の値に達します。以下の式は、勾配降下法を使用して係数がどのように更新されるかを示しています。

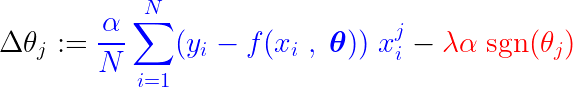
上の青い部分が λαそれ自体は非常に小さな数なので、 Δθj ほぼ着実な歩みです。 λα。このステップの信号(赤い部分)は次の要素に依存します。 sgn(θj)、その出力は θj。値が θj 正、つまりより大きい ε、 NS sgn(θj) 1に等しいので、 Δθj ほぼ等しい -λαゼロに近づきます。
係数をゼロにする定数ステップ (赤い部分) を抑制するには、損失関数の勾配 (青い部分) をステップ サイズよりも大きくする必要があります。損失関数の勾配を大きくするには、特徴値がモデル出力に大きな影響を与える必要があります。
このように、モデル出力とは関係のない値を持つ特徴、より正確にはその対応するパラメータは、トレーニング中に L1 正則化によってゼロにされます。
参考文献と結論
- このトピックについてさらに詳しく知るために、私はReddit r/MachineLearningに質問を投稿しました。ファローアップ さまざまな解釈が含まれているので、ぜひ読んでみてください。
- マディヤル・アイトバエフも 興味深いブログ 同じ質問をエンジニアリング的な説明とともに取り上げます。
- ブログ ブライアン・キングは確率論の観点から組織について説明します。
- .ا 議論 CrossValidated の Web サイトで、彼は L1 基準がスパース モデルを推奨する理由を説明しています。 ブログ Mukul Ranjan による詳細な記事では、L1 規範ではトランザクションがゼロになることが推奨されるのに、L2 規範では推奨されない理由について説明しています。
「L1 正則化は特徴を選択する」というのは、内部的にどのように動作するかについて詳しく述べなくても、ほとんどの ML 学習者が同意する単純な記述です。このブログは、質問に直感的に答えるために、私の理解とメンタルモデルを読者に提示する試みです。ご意見やご質問は、以下のメールアドレスまでご連絡ください。 私のウェブサイト。学び続けて素晴らしい一日をお過ごしください!
コメントは締め切りました。