

サイバーセキュリティのリーダーたちは、不可能と思われる質問に直面しています。 「今年、セキュリティ侵害が発生する可能性はどれくらいですか?」そして「いくらかかりますか?」そして「それを止めるにはどれくらいの費用がかかるのか?」
しかし、今日使用されているほとんどのリスク モデルは、依然としてデータではなく、推測、直感、色分けされたリスク マップに基づいています。
実際、私は PwCの2025年グローバルデジタルトラストインサイト調査 定量的リスクモデリングを実質的に使用している組織はわずか 15% です。
この記事では、従来のサイバーセキュリティ リスク モデルが不十分な理由と、確率モデルなどの軽量の統計ツールを適用することでどのようにより良い方法が得られるかについて説明します。

サイバーリスクモデリングにおける2つの主要な考え方
サイバーリスクモデルは次のとおりです。 サイバーセキュリティの脅威と、それが情報システム、データ、またはビジネスに及ぼす潜在的な影響を分析、評価、測定するために使用される体系的なフレームワークまたは方法。
情報セキュリティ専門家は、リスク評価プロセス中に、主に定性的および定量的という 2 つの異なるリスク モデリング手法を使用します。それは サイバーリスクの定量的モデリング 専門知識を必要とする高度な技術。
リスク評価のための定性モデル
4 つのチームが同じリスクを評価していると想像してください。リスクの可能性については 5/5 のスコア、影響については 5/3 のスコアが付けられます。相手チームは彼女に 5/4 と 5/XNUMX を与えます。両チームともマトリックス上でそれを見つけます。しかし、どちらも CFO の次の質問に答えることはできません。「これが実際に起こる可能性はどれくらいですか。また、コストはどれくらいかかりますか?」
定性的なアプローチは主観的なリスク評価に依存し、主に評価者の直感から生まれます。定性的なアプローチでは通常、リスクの発生可能性と影響度を 1 ~ 5 などの順序尺度で評価することになります。
次に、リスクがリスク マトリックス内に配置され、この順序尺度のどこに当てはまるかを理解します。
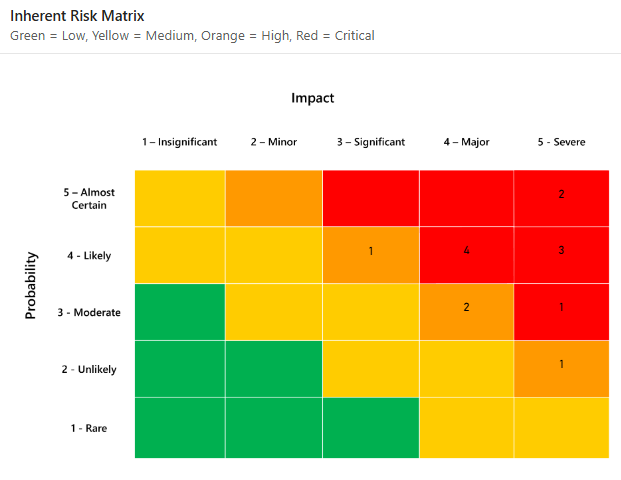
2 つの順序尺度は、発生可能性と影響に基づいて最も重要なリスクを優先順位付けするためによく使用されます。一見すると、情報セキュリティにおけるリスクの一般的な定義は次のとおりであるため、これは合理的に思えます。
[text{リスク} = text{発生可能性} × text{影響}]
しかし、統計的な観点から見ると、定性的なリスクモデリングには非常に重大なリスクが伴います。
こうしたリスクの 1 つ目は、順序尺度の使用です。順序尺度に数字を割り当てると、モデルが数学的にサポートされているように見えますが、これは単なる錯覚です。
順序尺度は単なるラベルであり、それらの間の距離は定義されていません。影響度が「2」のリスクと影響度が「3」のリスク間の距離は定量化できません。順序尺度のラベルを「A」、「B」、「C」、「D」、「E」に変更しても違いはありません。
これは、定性的なモデリングを使用する場合のリスクの定式化に欠陥があることを意味します。 「B」の確率に「C」の効果を掛けて計算することは不可能です。
もう一つの大きな落とし穴は、不確実性のモデリングです。サイバーリスクをモデル化する際には、不確実な将来の出来事をモデル化することになります。実際には、さまざまな結果が発生する可能性があります。
サイバーリスクを単一の推定値(「20/25」や「高」など)にまとめると、「最も可能性の高い年間損失は 1 万ドル」と「5 万ドル以上の損失が発生する可能性は 10%」という重要な違いが捉えられません。
定量的リスクモデリング:高度な分析
リスク評価を実施するチームを想像してください。彼らは、100万ドルから10万ドルまでの範囲の結果になると見積もっています。モンテカルロシミュレーションを実行すると、年間損失が10万ドルを超える可能性が480%あり、予想される損失はXNUMX万ドルであることがわかります。さて、CFOがこう尋ねたとします。 「これが起こる可能性はどのくらいありますか?そして、コストはいくらかかりますか?」チームは直感だけでなくデータに基づいて対応できます。
このアプローチは、漠然としたリスク分類から、 可能性と潜在的な経済的影響、経営者が理解できる言語です。
統計学の知識がある方なら、特に次の 1 つの概念に注目してください。
確率。
サイバーセキュリティリスクモデリングは、本質的には、特定のイベントが発生する可能性と、発生した場合の影響を定量化する試みです。これにより、モンテカルロシミュレーションなどのさまざまな統計ツールが利用できるようになります。モンテカルロシミュレーションでは、順序尺度よりもはるかに効果的に不確実性をモデル化できます。
定量的リスクモデリングでは、統計モデルを使用して損失にドル価値を割り当て、これらの損失イベントが発生する確率をモデル化し、将来の不確実性を捉えます。
定性分析では、最も可能性の高い結果を近似できる場合もありますが、「ロングテール リスク」と呼ばれる、まれではあるものの影響力のあるイベントなど、不確実性の全範囲を捉えることはできません。
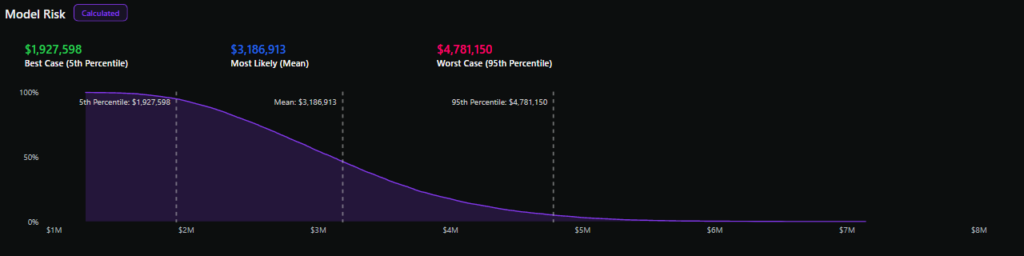
損失超過曲線は、y 軸に所定の年間損失額を超える確率、x 軸に異なる損失額をプロットし、下向きの線を形成します。
損失超過曲線から 90 パーセンタイル、中央値、XNUMX パーセンタイルなどのさまざまなパーセンテージを引き出すと、リスクの潜在的な年間損失を XNUMX% の信頼度で把握できます。
定性分析による一点推定では、最も可能性の高いリスクを概算できますが(評価者の判断の精度によって異なります)、定量分析では、まれではあるものの起こりうる結果の不確実性(「ロングテール リスク」と呼ばれる)も捕捉します。
サイバーリスクを超えて:サイバーセキュリティにおけるリスクモデルの改善
情報セキュリティにおけるリスク モデルを改善するには、外部、具体的には他の分野で使用されているテクノロジーに目を向けるだけで十分です。リスク モデルは、金融、保険、航空安全、サプライ チェーン管理など、さまざまなアプリケーションで大幅に進化しています。これらの分野は、サイバーセキュリティに適用できる貴重な洞察を提供します。
財務チームは、同様のベイズ統計を使用してモデルを使用し、投資ポートフォリオのリスクを管理します。一方、保険チームは高度な保険数理モデルを使用してリスクをモデル化します。航空業界では、確率モデルを使用してシステム障害のリスクをモデル化します。サプライチェーン管理チームは、確率シミュレーションを使用してリスクをモデル化します。これらの方法論は、効果的なサイバーリスクモデルを開発するための強固な基盤を提供します。
ツールはすでに存在します。数学的な基礎はよく理解されています。他の業界が道を切り開きました。今こそ、サイバーセキュリティが定量的リスク モデルを採用して、より優れた、より情報に基づいた意思決定を行い、サイバーセキュリティ戦略を改善し、潜在的な損失を削減するときです。これらの定量的モデルを採用することは、より効果的なサイバーリスク管理に向けた重要な一歩となります。
翻訳する
| アラノボの男性 | アラクミの神 |
| 順序尺度(1~5) | 確率モデル |
| 個人的な直感 | 統計的正確性 |
| 単一評価ポイント | リスク分布 |
| ヒートマップとカラーコード | 損失超過曲線 |
| 稀ではあるが深刻な事象を無視する | ロングテールリスクを捕捉 |
コメントは締め切りました。