

OpenAI o1 や DeepSeek-R1 のような推論モデルには、考えすぎの問題があります。 「1+1 はいくつですか?」のような簡単な質問をすると、彼女は答える前に数秒間考えます。

理想的には、AI モデルは人間と同様に、いつ直接回答を提供すべきか、いつ応答する前に考えるための追加の時間とリソースを割り当てるべきかを判断できる必要があります。そしてそれは 新しい技術 研究者による発表 メタAI وイリノイ大学シカゴ校 クエリの難易度に基づいて推論予算を割り当てるようにモデルをトレーニングします。その結果、応答が速くなり、コストが削減され、コンピューティング リソースの割り当てが改善されます。
高価な推論
大規模言語モデル (LLM) は、思考の連鎖 (CoT) と呼ばれる長い思考の連鎖を生成することで、推論タスクのパフォーマンスを向上させることができます。アイデア チェーン手法の成功により、モデルが問題についてより深く「考える」ことを強制し、複数の答えを生成して検討し、最適な答えを選択する一連の推論時間スケーリング手法が生まれました。
多数決(MV)は推論モデルで使用される主な方法の 1 つであり、複数の回答が生成され、最も頻繁に尋ねられる回答が選択されます。このアプローチの問題は、モデルが均一な動作を採用し、各入力を困難な推論問題として扱い、複数の回答を生成するために不必要なリソースを消費することです。
賢い推論
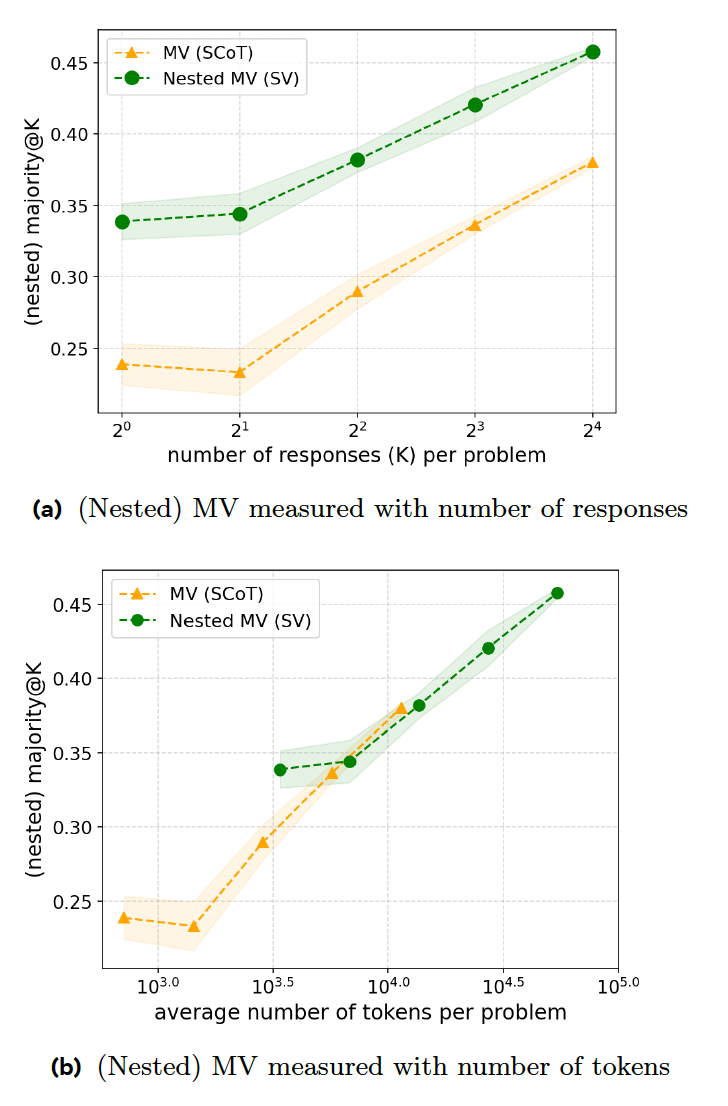
新しい研究論文では、推論モデルの応答効率を高める一連のトレーニング手法を提案しています。最初のステップは「順次投票」(SV)であり、特定の回答が一定回数出現するとモデルは推論プロセスを中止します。たとえば、フォームでは最大 8 つの回答を生成し、少なくとも 3 回表示される回答を選択するように求められます。モデルに上記の単純なクエリが与えられた場合、最初の 3 つの回答は類似している可能性が高く、早期に停止して、時間と計算リソースを節約できます。
彼らの実験では、同じ数の解答を生成する場合、数学競技問題において SV が従来の MV よりも優れていることが示されています。ただし、SV では追加の命令とコード生成が必要となるため、コードと精度の比率の点では MV と同等になります。
1 番目の手法である Adaptive Sequential Voting (ASV) は、モデルに問題を検査させ、問題が難しい場合にのみ複数の回答を生成するようにすることで SV を改善します。単純な問題 (1+XNUMX の主張など) の場合、モデルは投票プロセスを経ずに単一の回答を生成します。これにより、モデルは単純な問題と複雑な問題の両方をより効率的に処理できるようになります。
強化学習
SV 技術と ASV 技術はどちらもモデルの効率を向上させますが、大量の手動でラベル付けされたデータが必要になります。この問題を緩和するために、研究者らは「推論予算制約ポリシー最適化」(IBPO)を提案している。これは、クエリの難易度に基づいて推論パスの長さを調整するようにモデルに教える強化学習アルゴリズムである。
IBPO は、推論予算の制約内で大規模言語モデル (LLM) の応答を改善できるように設計されています。強化学習アルゴリズムにより、モデルは、ASV 軌跡を継続的に生成し、応答を評価し、正しい回答と最適な推論予算を提供する結果を選択することにより、手動でラベル付けされたデータのトレーニングによって得られるゲインを上回ることができます。
彼らの実験では、IBPO によってパレート最適解が改善されることが示されており、つまり推論予算が固定されている場合、IBPO でトレーニングされたモデルは他のベースラインよりも優れたパフォーマンスを発揮します。
これらの研究結果は、現在の AI モデルが苦戦していると研究者が警告する中で発表された。企業は高品質のトレーニング データを見つけるのに苦労しており、モデルを改善するための代替方法を模索しています。
有望な解決策の 1 つは強化学習です。強化学習では、モデルに目標が与えられ、モデルが独自の解決策を見つけられるようになります。これは、手動でラベル付けされた例でモデルをトレーニングする教師あり微調整 (SFT) とは対照的です。
驚くべきことに、このモデルは人間が考えつかなかった解決策をしばしば見つけます。これは、アメリカの AI 研究所の優位性に挑戦した DeepSeek-R1 で効果を発揮したと思われる方式です。
研究者らは、「プロンプトベースの手法とSFTは絶対的な最適化と効率化に苦労しており、SFTだけでは自己修正機能を実現できないという仮説を裏付けている。この観察結果は同時並行研究によっても裏付けられており、この自己修正行動はプロンプトやSFTによって手動で生成されるのではなく、強化学習中に自発的に出現することを示唆している」と指摘している。
コメントは締め切りました。