

最新の Transformer ビジョン モデルでは、ノイズを追加して 2D および 3D オブジェクトの検出パフォーマンスを向上させます。この記事では、このメカニズムがどのように機能するかを学び、トレーニング プロセスでのノイズ除去などのテクニックの使用に焦点を当てて、オブジェクト検出モデルの精度向上への貢献について説明します。

早期視覚のためのトランスフォーマーモデル
DETR – DEtection TRansformer (Carion、Massa et al. 2020) は、物体検出用の最初のTransformerアーキテクチャの500つであり、学習したエンコーダー-デコーダークエリを使用して、画像トークンから検出情報を抽出しました。これらのクエリはランダムに初期化され、アーキテクチャではこれらのクエリにアンカーのようなオブジェクトを学習させるような制約は課されませんでした。 Faster-RCNN でも同様の結果が得られましたが、収束が遅いという欠点があり、トレーニングには 2024 エポック必要でした (DN-DETR、Li et al.、2020)。最近の DETR ベースのアーキテクチャでは、クエリが画像内の特定の領域のみに焦点を当てることを可能にする変形可能プーリングが使用されていました (Zhu ら、「Deformable DETR: Deformable Transformers For End-To-End Object Detection」、2022 年)。一方、他のアーキテクチャ (Liu ら、「DAB-DETR: Dynamic Anchor Boxes Are Better Queries For DETR」、XNUMX 年) では、初期クエリでエンコードされた空間アンカー (アンカーベースの CNN と同様に k-means を使用して生成) が使用されていました。スキップ接続により、Transformer デコーダー ブロックはアンカーからの勾配値として正方形を学習するようになります。変形可能な注意レイヤーは、事前にコード化されたアンカーを使用して画像から空間的な特徴をサンプリングし、それを使用して注意トークンを生成します。トレーニング中に、モデルは使用する理想的なアンカーを学習します。このアプローチは、モデルにボックス サイズなどの機能をクエリで明示的に使用するように教えます。
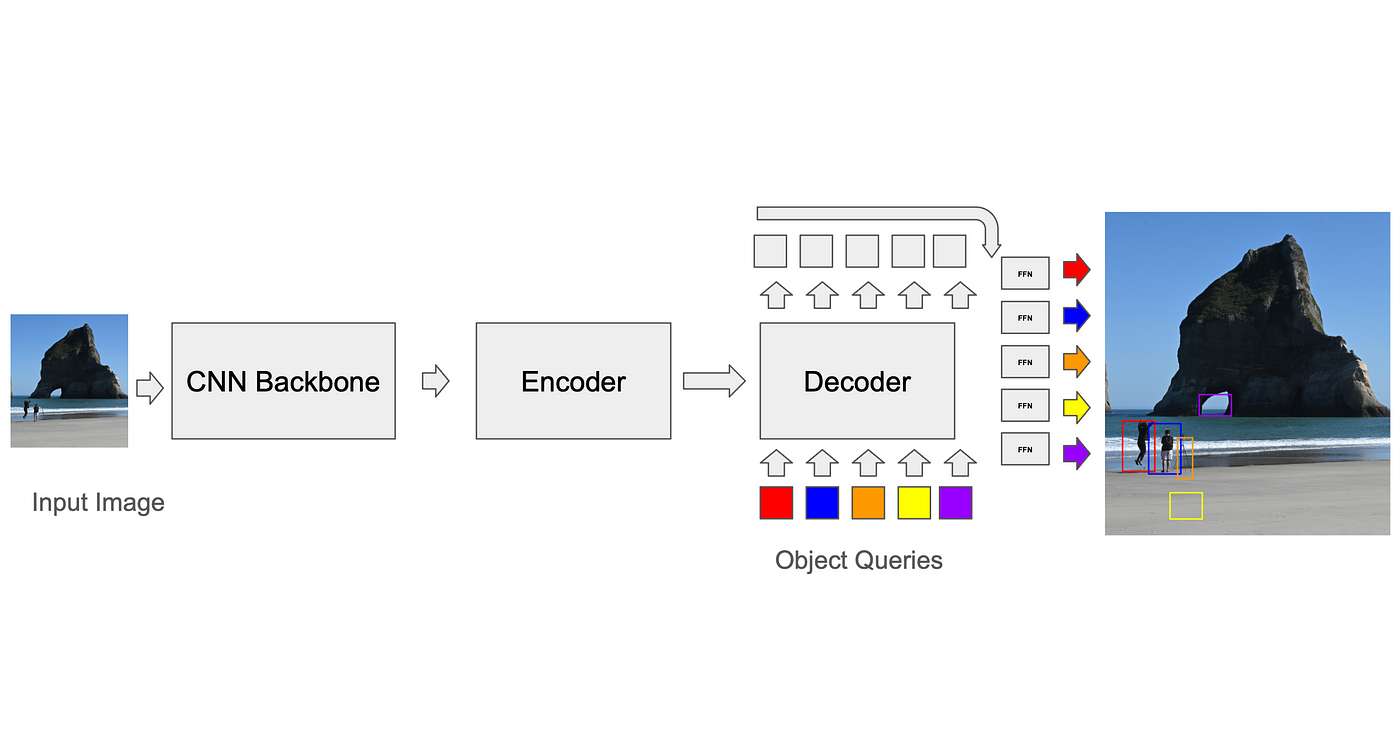
予測と現実の一致:バイナリマッチングアルゴリズム
損失を計算するには、トレーナーはまずモデルの予測をグラウンド トゥルース (GT) ボックスと一致させる必要があります。アンカーベースの CNN ではこの問題に対する比較的簡単な解決策がありますが (たとえば、各アンカーはトレーニング中にそのボクセル内の GT ボックスにのみ一致させることができ、推論では重複検出を除去するために非最大抑制が使用されます)、DETR によって開発されたトランスフォーマーの標準では、ハンガリアン アルゴリズムと呼ばれるバイナリ マッチング アルゴリズムが使用されます。各反復で、アルゴリズムは予測と実際の値との間の最適な一致(すべてのボックスにわたって合計されたボックスコーナー間の平均二乗距離などのコスト関数を最適化する一致)を見つけます。次に、予測値とグラウンドトゥルースのペア間の損失を計算し、バックプロパゲーションすることができます。過剰予測(GT マッチングのない予測)では離散的な損失が発生し、信頼スコアが低下します。このプロセスは、モデルの精度を向上させ、エラーを減らすために必要です。
問題
ハンガリーアルゴリズムの時間計算量は o(n³) です。興味深いことに、これは必ずしもトレーニングの品質のボトルネックになるわけではありません。「安定した結婚の問題:物理学者の観点からの学際的レビュー」(Fenoaltea 他、2021 年)では、アルゴリズムが不安定であることが示されています。つまり、目的関数の小さな変更がマッチング結果の大きな変更につながり、クエリのトレーニング目標に一貫性がなくなる可能性があります。トランスフォーマーのトレーニングの実際的な意味合いは、オブジェクト クエリがオブジェクト間をジャンプする可能性があり、収束に最適な機能を学習するのに長い時間がかかることです。言い換えれば、アルゴリズムの不安定性によりトレーニング プロセスが変動し、最良の結果に到達するまでに長い時間が必要になります。
DN-DETR(ノイズ除去による物体検出)
Liら不安定なマッチング問題に対するエレガントな解決策を提案し、この解決策は後に DINO、Mask DINO、Group DETR など他の多くの研究に採用されました。
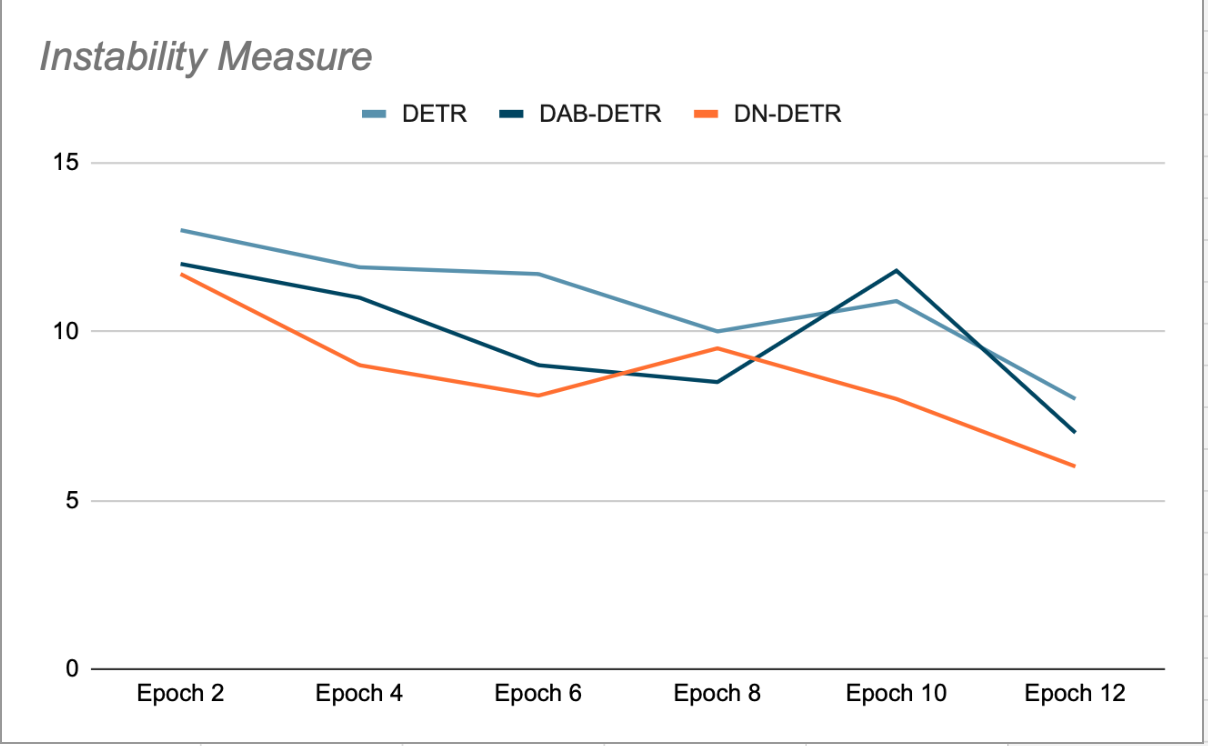
DN-DETRの主なアイデアは、トレーニングを強化することです。 簡単に傾斜できる仮想ピボットポイントマッチングプロセスをスキップします。これは、トレーニング中にGT(真の地面)タイルに少量のノイズを追加し、これらのノイズの多いタイルをデコーダークエリのアンカーとして供給することで行われます。DNクエリはオーガニッククエリからマスクされ、その逆も同様です。これは、トレーニングを妨げる可能性のあるクロスアテンションを回避するためです。これらのクエリによって生成された検出は、ソースGTタイルに既にマッチングされているため、二部マッチングを必要としません。DN-DETRの著者は、各エポックの終了時の検証フェーズ(ノイズ除去がオフになっているフェーズ)で、これによりDETRおよびDAB-DETRと比較してモデルの安定性が向上することを示しました。つまり、Plusクエリは、連続するエポックでGTオブジェクトとのマッチングが一貫しているということです(図2を参照)。
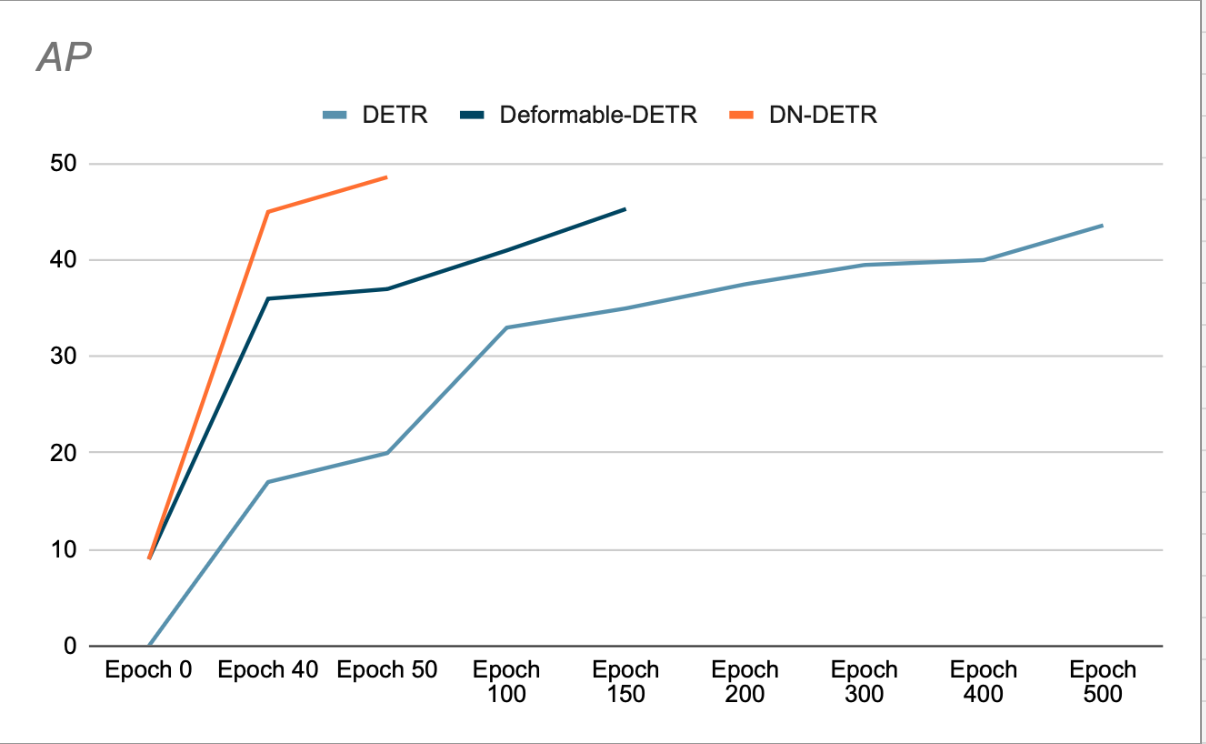
著者らは、DN を使用すると収束が高速化され、より優れた検出結果が得られることを示しています。 (図3参照)彼らの除去研究では、ResNet-1.9 をバックボーンとして使用した場合、以前の SOTA (DAB-DETR、AP 42.2%) と比較して、COCO 検出データセットで AP (平均精度) が 50% 増加したことが示されています。
DINOとコントラストノイズ除去
DINO はこのアイデアをさらに発展させ、ノイズ除去メカニズムに対照学習を追加しました。つまり、正の例に加えて、DINO は各 GT の別のノイズ バージョンを作成します。このバージョンは、正の例よりも GT から遠く離れるように数学的に構築されています (図 4 を参照)。このバージョンはトレーニングの負の例として使用されます。モデルは、真実に最も近い検出を受け入れ、遠い検出を拒否することを学習します (「オブジェクトなし」クラスを予測することを学習することにより)。
さらに、DINO は、コントラストノイズ除去 (CDN) のための複数のクラスタリング (GT オブジェクトごとに複数のノイズ アンカー) を可能にし、各トレーニング反復を最大限に活用します。
DINO の著者らは、CDN を使用した場合の平均精度 (AP) は 49% (COCO val2017) であると報告しました。
Sparse4Dv3 など、フレームからフレームへとオブジェクトを追跡する必要がある最新の時間モデルでは、CDN を使用し、時間的なノイズ除去グループを追加します。このグループでは、成功した DN アンカーの一部が (学習した非 DN アンカーとともに) 後続のフレームで使用するために保存され、オブジェクト追跡におけるモデルのパフォーマンスが向上します。

議論
ノイズ除去 (DN) により、ビジョン トランスフォーマー検出器の収束速度と最終的なパフォーマンスが向上するようです。しかし、上記のようなさまざまな方法の発展を検討すると、次のような疑問が生じます。
- DN は学習可能なアンカーを使用するモデルを改善します。しかし、学習可能なアンカーは本当に重要なのでしょうか? DN は学習不可能なアンカーを使用するモデルも改善しますか?
- DN がトレーニングにもたらす主な貢献は、二部マッチングをバイパスすることで勾配降下プロセスの安定性を高めることです。しかし、バイナリ マッチングが存在する主な理由は、トランスフォーマー作業の標準としてクエリの空間的制約を回避することにあるようです。では、クエリを特定の画像の場所に手動で制限し、バイナリ マッチングを放棄した場合(または各画像パッチで個別に実行されるバイナリ マッチングの簡略化されたバージョンを使用した場合)、DN によって結果はまだ改善されるでしょうか?
これらの疑問に明確な答えを与えてくれる作品は見つけられませんでした。私の仮説は、学習不可能なアンカー(アンカーがあまりまばらでない場合)と空間的に制約されたクエリを使用するモデルは、1. バイナリ マッチング アルゴリズムを必要とせず、2. アンカーが既にわかっており、他の一時的なアンカーからの回帰を学習してもメリットがないため、トレーニングで DN のメリットが得られないというものです。
アンカーが固定されていても散在している場合は、一時的なアンカーを使用すると降下が容易になり、トレーニング プロセスをスムーズに開始できることがわかります。
Anchor-DETR(Wand et al.、2021)は、学習可能なアンカーと学習不可能なアンカーの空間分布とそれぞれのモデルのパフォーマンスを比較しますが、私の意見では、学習可能性はモデルのパフォーマンスにそれほど価値を追加しません。注目すべきは、どちらの方法でもハンガリーアルゴリズムを使用しているため、バイナリマッチングを放棄してもパフォーマンスを維持できるかどうかは不明であるということです。
念頭に置いておくべきことの 1 つは、推論で NMS を回避する生産的な理由がある可能性があり、トレーニングではハンガリー アルゴリズムの使用が推奨されることです。
ノイズ除去が本当に重要になるのはどこでしょうか?私の意見では トレーサビリティ。追跡では、モデルにビデオ ストリームが提供され、連続するフレームにわたって複数のオブジェクトを検出するだけでなく、検出された各オブジェクトの一意の ID を維持することも必要です。時間的トランスフォーマー モデル、つまりビデオ ストリーミングの順次的な性質を利用するモデルは、個々のフレームを個別に処理しません。代わりに、以前の発見を保存するバンクを維持します。トレーニングでは、追跡モデルは、単に最も近い固定点から回帰するのではなく、前のオブジェクト検出(より正確には、前のオブジェクト検出に関連付けられた固定点)から回帰するように促されます。これまでの発見は、安定因子の固定されたネットワークに限定されないため、DN によって刺激される柔軟性が有益であると考えられます。これらの問題を取り上げた今後の著作をぜひ読んでみたいと思います。
ノイズ除去とビジョントランスフォーマーへの貢献については以上です。もしこの記事が気に入ったら、ディープラーニングと機械学習に関する他の記事もぜひ読んでみてください。 コンピュータービジョン!
コメントは締め切りました。