

生成 AI (GenAI) は急速に進化しており、楽しいチャットボットや印象的な画像生成だけにとどまらなくなりました。 2025年は、AIをめぐる誇大宣伝を実際の価値に変えることに焦点が当てられる年です。世界中の企業が、ユーザーへのサービス向上、効率性の向上、競争力の維持、成長の促進を目的として、自社の製品や業務に GenAI を統合し活用する方法を模索しています。大手プロバイダーの API と事前トレーニング済みモデルにより、GenAI の統合はこれまで以上に簡単になりました。しかし、問題の核心は次のとおりです。 統合が簡単だからといって、AI ソリューションが導入後に意図したとおりに機能するとは限りません。

予測モデルは実際には新しいものではありません。私たち人間は、正式には統計から始まって、何年も前から物事を予測してきました。しかし、 GenAI はさまざまな理由から予測の分野に革命をもたらしています。:
- AI ソリューションを構築するために、独自のモデルをトレーニングしたり、データ サイエンティストになる必要はありません。
- AI はチャット インターフェースを通じて簡単に使用できるようになり、API を通じて簡単に統合できるようになりました。
- これまでは不可能だった、または非常に困難だった多くのことが可能になります。
これらすべてが GenAI は非常にエキサイティングですが、リスクも伴います。。従来のソフトウェアや従来の機械学習とは異なり、GenAI は新たなレベルの予測不可能性を提供します。決定論的なロジックを実装しているのではなく、大量のデータでトレーニングされたモデルを使用して、必要に応じて応答することを期待しています。では、AI システムが意図したとおりに動作しているかどうかはどうすればわかるのでしょうか?実行の準備ができているかどうかはどうすればわかりますか?その答えは評価です。この投稿ではこの概念について詳しく説明します。
- Genai システムを従来のソフトウェアや従来の機械学習 (ML) と同じ方法でテストできない理由
- AI システムの品質を理解するために評価が不可欠であり、オプションではない理由 (サプライズが好きな場合を除く)
- さまざまな種類の評価とそれを実際に適用するための手法
プロダクト マネージャー、エンジニア、あるいは AI に携わっている方や AI に興味がある方であれば、この記事が AI システムの品質について批判的に考える方法 (そしてその品質を実現するために評価が不可欠である理由) を理解する一助になれば幸いです。
生成 AI は、従来のソフトウェアや従来の機械学習のようにテストすることはできません。
従来のソフトウェア開発ではシステムは決定論的なロジックに従います。 X が起きれば、Y が起きるでしょう。 - いつも。プラットフォームに問題が発生した場合や、コードにバグが導入された場合を除いて、テスト、監視、アラートを追加します。単体テストは小さなコードブロックを検証するために使用され、統合テストはコンポーネントが適切に動作することを確認するために使用され、監視は運用環境で何かが壊れているかどうかを検出するために使用されます。従来のソフトウェア テストは、電卓の動作をチェックするようなものです。 2 + 2 を入力し、4 を期待します。真か偽かは明らかかつ必然的です。
しかし、機械学習と人工知能は不確定性と確率を導入します。ルールを通じて動作を明示的に指定する代わりに、データからパターンを学習するようにモデルをトレーニングします。 AI では、X が発生した場合、出力はハードコードされた Y ではなく、トレーニング中にモデルが学習した内容に基づいて、ある程度の確率を伴う予測になります。。これは非常に強力ですが、不確実性も生じます。つまり、同一の入力が時間の経過とともに異なる出力を生成したり、妥当と思われる出力が実際には間違っている場合があり、まれなシナリオで予期しない動作が発生する場合があります...
これにより、従来のテスト方法は不十分となり、場合によっては実行不可能になります。計算機の例は、自由形式の試験における生徒の成績を評価しようとする試みに近いものです。それぞれの質問と、その質問に答える多くの可能な方法に対して、与えられた答えは正しいでしょうか?それは学生が持つべき知識レベルを超えていますか?生徒はすべてをでっち上げたのに、とても説得力があるように聞こえますか?試験の答えと同じように、 AI システムは評価できますが、さまざまな入力、コンテキスト、ユースケースに適応するには、より一般化され柔軟な方法が必要です。 (またはテストの種類)。
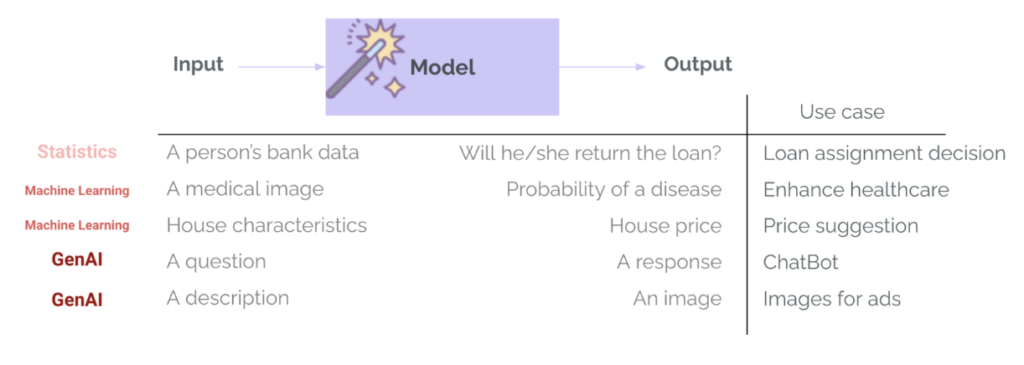
في 機械学習 従来 (ML)、評価はプロジェクト ライフサイクルの一部としてすでに確立されています。。ローンの承認や病気の検出などの限定されたタスクでモデルをトレーニングする場合は、常に、精度、再現率、RMSE、MAE などの指標を使用した評価ステップが含まれます。これは、モデルのパフォーマンスを測定し、さまざまなモデル オプションを比較し、モデルが展開に移行するのに十分であるかどうかを判断するために使用されます。 GenAI では、これは通常変わります。チームは、すでにトレーニング済みで、モデル プロバイダーによる内部評価および公開ベンチマークでの汎用評価に合格したモデルを使用します。これらのモデルは、質問に答えたり、電子メールを作成したりするといった一般的なタスクに非常に優れているため、特定のユースケースでは過度に信頼してしまうリスクがあります。しかし、「この素晴らしいテンプレートは私の使用ケースに十分でしょうか?「ここで評価が重要になります。」 – 予測または生成が特定のユースケース、コンテキスト、入力、およびユーザーに適しているかどうかを評価します。

ML と GenAI の間には、モデルの出力の多様性と複雑さというもう 1 つの大きな違いがあります。カテゴリと確率 (顧客がローンを返済する確率など) や数値 (住宅の特徴に基づいた予想価格など) は返されなくなりました。 GenAI システムは、長さ、トーン、内容、形式が異なるさまざまなタイプの出力を返すことができます。同様に、これらのモデルは、高度に構造化された特定の入力を必要とせず、通常はテキスト、画像、さらには音声やビデオなど、ほぼすべての種類の入力を受け入れます。したがって評価はさらに難しくなります。
評価は必須であり、オプションではない理由(不快なサプライズを好まない限り)
評価は、AI システムが実際に意図したとおりに動作しているかどうかを測定するのに役立ちます。 あなたはそれを望んでいるシステムが運用の準備ができているかどうか、また、準備ができている場合は、期待どおりに動作し続けているかどうかを確認します。評価が重要な理由の分析は次のとおりです。
- 品質評価: 評価は、AI 予測または出力の品質と、それらが全体的なシステムおよびユースケースにどのように統合されるかを理解するための構造化された方法を提供します。回答は正確ですか?役に立つ?凝集性?関連している?
- エラーを定量化する: 評価は、エラーの割合、種類、および大きさを判断するのに役立ちます。エラーはどのくらいの頻度で発生しますか?最も頻繁に発生するエラーの種類は何ですか (例: 誤検知、幻覚、フォーマット エラー)?
- リスク軽減: 有害または偏った行動がユーザーに届く前にそれを検出して防止し、評判リスク、倫理的問題、潜在的な規制問題から企業を保護します。
自由な入力と出力の関係と長文テキスト生成を備えた生成 AI により、評価はより関連性が高く複雑になります。物事がうまくいかないときは、非常に悪い方向に進む可能性があります。チャットボットが危険なアドバイスを提供したり、モデルが偏ったコンテンツを生成したり、AI ツールが誤った事実を幻覚させたりといったニュースの見出しを私たちは皆見たことがあるでしょう。
「AI が完璧になることは決してありませんが、評価を使用することで、金銭や信頼性、Twitter での話題性を失う可能性のある恥ずかしい思いをするリスクを軽減できます。「
AI 評価戦略をどのように定義しますか?

では、AI の評価はどうやって決定するのでしょうか?すべての人に当てはまる評価方法はありません。評価は特定のユースケースによって異なり、AI アプリケーションの特定の目標と一致する必要があります。たとえば、検索エンジンを構築している場合、結果の関連性が重要になるかもしれません。チャットボットの場合は、有用性と安全性を気にするかもしれません。機密情報であれば、正確性と精度が重要になると思われます。複数のステップを含むシステム(検索を実行し、結果に優先順位を付けて、回答を生成する AI システムなど)の場合、多くの場合、各ステップを評価する必要があります。ここでの考え方は、各ステップが全体的な成功指標の達成に役立つかどうかを測定することです (そして、これに基づいて、反復と改善の焦点をどこに置くべきかを理解します)。
一般的な評価領域は次のとおりです。
- 正しさと幻覚: 出力は現実的に正確ですか?システムは不正確な情報や幻覚を生成しますか?
- 関連性: コンテンツはユーザークエリまたは提供されたコンテキストと一致していますか?
- 安全性、偏見、毒性
- 形式: 出力は期待される形式 (JSON、有効な関数呼び出しなど) になっていますか?
- 安全性、バイアス、毒性: システムは有害、偏向的、または有毒なコンテンツを生成しますか?
タスク固有のメトリック。 たとえば、分類タスクでは精度や適合度などのメトリックが使用され、要約タスクでは ROUGE または BLEU が使用され、正規表現コード生成およびエラーのない実行検証タスクでは精度や適合度などのメトリックが使用されます。
評価は実際にはどのように計算されるのでしょうか?
測定対象を決定したら、次のステップはテスト ケースを設計することです。これは、次のような一連の例です (多ければ多いほど良いですが、常に価値とコストのバランスをとります)。
- 入力例:システムが本番稼働に入った後の現実的な紹介。
- 期待される出力 (該当する場合): 重要な事実または望ましい結果の例。
- 評価方法: 結果を評価するための記録メカニズム。
- 結果または成功/失敗: テスト ケースを評価する計算メトリック。
ニーズ、時間、予算に応じて、評価方法として使用できる手法がいくつかあります。
- 次のような統計記録ツール: BLEU、ROUGE、METEOR、または埋め込み間のコサイン類似度測定 – 生成されたテキストを参照出力と比較するのに適しています。
- 従来の機械学習指標としては、 精度、再現率、AUC – ラベル付きデータによる分類に最適です。
- 大規模言語モデルを裁判官として(LLM-as-a-Judge) 大規模な言語モデルを使用して出力を評価します(例:「この回答は正しくて役に立ちますか?(「)」)。特に、分類されていないデータが利用できない場合や、オープンエンド構造を評価する場合に便利です。
コードベースの評価 正規表現、ロジックルール、またはテストケース実装を使用してフォーマットを検証します。
結論
具体的な例を挙げてすべてをまとめてみましょう。顧客サポート チームが受信メールの優先順位付けを行えるように、感情分析システムを構築しているとします。
目標は、最も緊急性の高いメッセージや否定的なメッセージに迅速に対応し、フラストレーションを軽減し、満足度を高め、顧客離れを低下させることです。これは比較的単純な使用例ですが、出力が限られているこのようなシステムでも、品質は重要です。予測が間違っていると、電子メールの優先順位がランダムに決定され、チームがコストのかかるシステムで時間を無駄にしてしまう可能性があります。
では、ソリューションが期待どおりに機能しているかどうかをどのように確認すればよいのでしょうか?評価中です。この特定のユースケースで評価する上で関連する可能性がある項目の例をいくつか示します。
- フォーマット検証: 電子メールの感情を予測するための大規模言語モデル (LLM) 呼び出しの出力は、期待される JSON 形式で返されますか?これは、正規表現、スキーマ検証などのコードベースのチェックによって評価できます。
- 感情分類の精度: システムは、短いテキスト、長いテキスト、多言語のテキストなど、さまざまなテキストにわたって感情を正しく分類できますか?これは、従来の機械学習メトリクス (ML メトリクス) を使用してラベル付けされたデータを使用して評価できます。ラベルが利用できない場合は、大規模言語モデル (LLM) を判断基準として使用します。
ソリューションが稼働したら、ソリューションの最終的な影響に最も関連する指標も含める必要があります。:
- 優先順位付けの有効性: サポートエージェントは実際に最も重要なメールに誘導されていますか?優先順位は、望ましいビジネスへの影響と一致していますか?
- 最終的なビジネスへの影響: 時間が経つにつれて、このシステムは応答時間を短縮し、顧客離れを減らし、満足度スコアを向上させますか?
評価は、AI システムが有用、安全、価値があり、実稼働ユーザーにとって準備が整ったものになるように構築するために不可欠です。 したがって、単純な分類器を使用する場合でも、オープンエンドのチャットボットを使用する場合でも、「十分に良い」(最低限の実行可能な品質) が何を意味するかを定義する時間を取り、それに基づいて評価を構築して測定してください。
参照
【1] AI製品には評価が必要ですハメル・フセイン
【2] LLM評価指標:究極のLLM評価ガイド、Confident AI
【3] AIエージェントの評価、deeplearning.ai + Arize
コメントは締め切りました。