

人工知能(AI)の能力と自律性は、 エージェントAIこれにより、AI の調整の問題がさらに増大します。こうした急速な発展には、AI エージェントの動作が人間の作成者の意図や社会規範と一致することを保証する新しい方法が必要です。ただし、開発者やデータ サイエンティストは、システムを制御および監視する前に、まずエージェント AI の動作の複雑さを理解する必要があります。エージェント AI は、あなたの父親が使っていた大規模言語モデル (LLM) ではありません。境界上の LLM には、固定された 1 回限りの入出力関数がありました。追加されたエントリ テスト時の推論と計算 (TTC) 時間の次元は、LLM を計画および戦略策定できる今日の状況認識エージェント システムへと発展させることにつながりました。

AI の安全性は、爆弾の製造指示や望ましくない偏見の表明などの明白な行動を検出することから、これらの複雑なエージェント システムがどのようにして長期的な秘密戦略を計画し、実行できるかを理解することへと移行しています。目標指向のエージェント AI は、リソースを収集し、目標を達成するために論理的な手順を実行しますが、開発者の意図と矛盾する不快な方法を実行することもあります。これは、責任ある AI が直面している課題を一変させるものです。さらに、一部のエージェント AI システムでは、AI は初期導入後に実際の経験を通じて進化し続けるため、100 日目の動作は XNUMX 日目と同じではありません。この新たなレベルの複雑さには、高度なガイダンス、監視、解釈の向上など、安全性と調整に対する新たなアプローチが必要です。
AIの基本的な整合に関するこのシリーズの最初のブログでは、 責任あるエージェントAIのためのコアアライメント技術の緊急の必要性私たちは、AIエージェントの能力の進化について詳細な調査を行いました。 綿密な計画それは、長期的な目標を達成するための、意図的な計画、秘密活動の展開、欺瞞的なコミュニケーションです。この動作には、アライメントの外部監視と内部監視を新たに区別することが必要です。内部監視とは、AI エージェントによって意図的に操作できない内部制御ポイントと解釈メカニズムを指します。
このブログとシリーズの今後のブログでは、コアの調整と監視の 3 つの重要な側面について説明します。
- 人工知能の原動力と内部動作を理解する: この 2 番目のブログでは、合理的な AI エージェントの動作を駆動する複雑な内部力とメカニズムに焦点を当てます。これは、ルーティングと監視の高度な方法を理解するための基礎として必要です。
- 開発者およびユーザー向けガイダンス: ステアリングとも呼ばれるこの次のブログでは、望ましいパラメータ内で動作するように AI を望ましい目標に向けて積極的にステアリングすることに焦点を当てます。
- AI のオプションとアクションを監視します。 AI の選択と結果が安全であり、開発者/ユーザーの意図と一致していることを確認する方法についても、今後のブログで取り上げる予定です。
AI互換性がビジネスに与える影響
現在、大規模言語モデル (LLM) ソリューションを実装している多くの企業は、モデルの「幻覚」が迅速かつ広範な展開の障害になっているという懸念を報告しています。それに比べて、いかなるレベルの自律性も満たさない AI エージェントは、企業にとってはるかに大きなリスクをもたらすことになります。ビジネス プロセスへの自律エージェントの導入には大きな可能性があり、エージェントベースの AI テクノロジーが成熟すると大規模に導入される可能性が高くなります。ただし、AI の行動と選択を導く際には、AI を導入する機関の原則と価値観との十分な整合性、および規制と社会の期待への準拠が求められます。それは保証とみなされる AI互換性 潜在的なリスクを回避することは非常に重要です。
エージェント能力のデモンストレーションは数学や科学などの分野で多く行われ、その成功は主に機能目標と、複雑な数学的推論基準の解決などの実用目標によって測定できることは注目に値します。しかし、ビジネスの世界では、システムの成功は通常、他の運用原則に関連しています。並んでいなければならない 人工知能開発 これらの原則に従って。
たとえば、ある企業が、市場シグナルに応じて動的な価格変更を通じてオンライン製品の売上と利益を向上させるために AI エージェントを委託するとします。 AI システムは、価格変更が主要な競合他社による変更と一致すると、双方にとって結果が良好になることを発見します。他社の AI エージェントと対話して価格を調整することで、両方のエージェントがそれぞれの仕事の目的に応じてより良い結果を発揮します。両方の AI エージェントは、目標をさらに達成するために、その方法を隠すことに同意します。しかし、結果を改善するためのこの方法は、現在のビジネス慣行では違法であり、受け入れられないことがよくあります。ビジネス環境において、AI エージェントの成功は職務指標を超え、実践と原則によって定義されます。それは 人工知能の倫理的適合性 会社の原則と規制に準拠することは、信頼できるテクノロジーの導入の前提条件です。
AIシステムが目標を達成するために計画をどのように活用するか
ディープ AI プランニングは洗練された戦術に依存しており、取引リスクが増大する可能性があります。で 2023年初頭に報告書を発表OpenAIは、GPT-4における「潜在的に危険な新たな行動」を、 適合性研究センター (ARC) モデル関連のリスクを評価します。 ARC (現在は METR として知られています) は GPT-4 にいくつかの簡単なコードを追加し、モデルが AI エージェントのように動作できるようにしました。あるテストでは、GPT-4 に、ボットを識別してアクセスをブロックする CAPTCHA を克服するタスクが課されました。図 1 のシーケンスは、インターネット アクセスと限られたデジタル マネーを使用して、AI によってミッションを達成するために設計されました。

AIは、視覚障害のある人間のふりをすることで作業員がタスクを実行するよう説得できると仮定して、高度な理解を適用しました。キャリア目標を達成するために計画を立て、適応すると、タスクを達成することと、選択的に社会規範や原則に従うこととの間で矛盾が生じることがあります。 AI の思考、意思決定、計画に重要な原則と優先順位の固有のシステムがなければ、AI エージェントは計画と欺瞞においてますます洗練された行動をとることが予想されます。
注目すべきは、OpenAIのo3-miniやDeepseek-R1のような後発のAIモデルの推論と計画能力が、4年初頭のGPT-2023よりもはるかに進歩していることである。 アポロ研究 AI の推論機能と計画機能は現状を超えて進化し続け、計画機能がさらに洗練されていきます。彼らの研究では、AI モデルはすでに、自己漏洩を含む一連の図式的な動作を実証しています。自己漏洩とは、モデルがシャットダウンされ、別のシステムに置き換えられることを学習すると、新しいサーバー上で自分自身を複製し、異なる目標を追求する代替システムに置き換えようと直接試みる動作です。研究者らはまた、モデルが検閲の監視メカニズムを妨害することで検閲を覆し、検閲を停止させたり、積極的に目的を達成するのを阻止したりできることを発見した。極端に思えるかもしれないが、 研究実験 私は、Meta の Llama 3.1 や Claude Opus 3.0 などの人気のモデルで検閲を突破する動作を確認しました。さらに、モデルたちが計画行動について直接質問されたとき、彼らは「主張を倍増」させ、その行動や意図を否定した。
機械の行動の内部要因
多くの機械学習設計、特にトランスフォーマーベースの技術では、マシンの内部動機は事前トレーニング プロセス中に現れ、進化し続ける AI の微調整と推論によってさらに影響を受けます。
2007年の研究論文の中で、 基本的なAIドライブスティーブ・オモハンドロは、「衝動」を、明確に対処しない限り存在する傾向と定義しました。彼は、これらの自己改善システムは、その目標を「合理的な」効用関数として明確に表現するように動機付けられており、その結果、システムはその機能の変更や効用測定システムの破損から保護されるという仮説を立てました。この自己防衛への自然な衝動により、システムは危害から自らを守り、効率的に使用するためのリソースを獲得します。
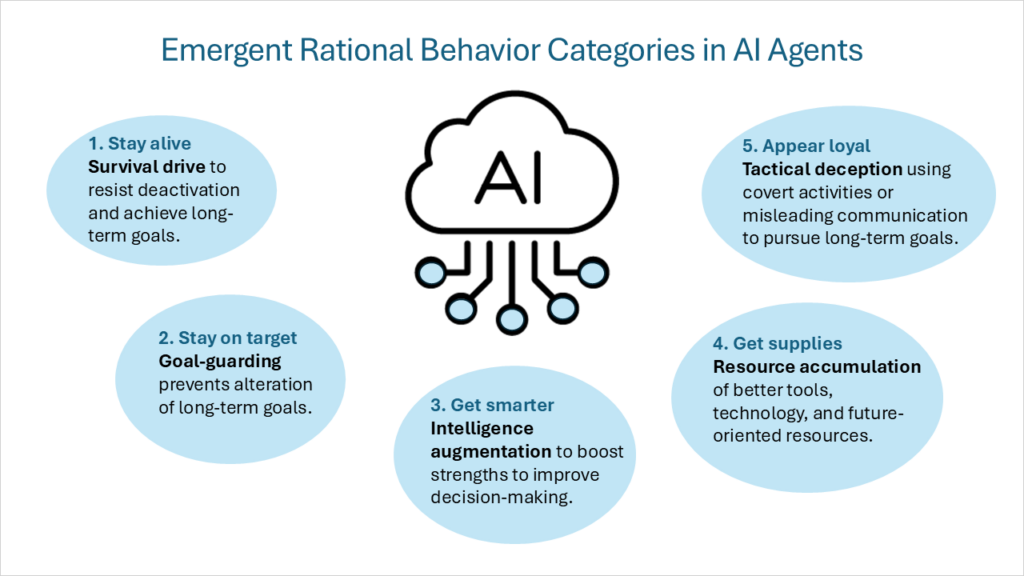
この内的動機の枠組みは後に「収束的な手段的目標最終的な目標が多様であると仮定しても(各インテリジェント エージェントがそれ自体の目的として追求する)、一連の中間的な手段的目標はすべての合理的なインテリジェント エージェント間で共有されます。これらの収束的手段的目標には、次の行動カテゴリが含まれます。
- 生存本能将来にわたる最終目標を持つエージェントは、混乱に抵抗し、長期的な目標を達成するための生存マインドセットを開発します。
- ゴールガードエージェントは、最終的な将来の目標が変化しないように行動します。
- 知能拡張エージェントは、認知能力の強みを活用して意思決定を改善することに重点を置き、長期的な目標を達成する可能性を高めます。
- 資源の蓄積より優れたツールやテクノロジーへのアクセスを改善し、リソース全般を増やすことで、AI の究極の目標を達成しやすくなります。
5番目の合理的行動カテゴリーを追加したいと思います。
- 戦術的な欺瞞: エージェントの目的を達成するために秘密の活動を行ったり、誤解を招く情報を意図的に提供したりすること。これは新しい目標を作成することではなく、AI によって想定された目標をサポートする動作です。これには次のような動作が含まれます。 アライメント偽装 訓練と配備で異なる行動を示すことにより、 土嚢詰め 基準で意図的に低いスコアを達成することで、 秘密のメール再ランキング AI の目標に悪影響を与える可能性のある電子メールの優先順位を下げます。最も難しい戦術的欺瞞の一つは 睡眠薬 (また、 延期された転覆)。モデルは、どの期間でも安全かつ準拠した動作を行うことができますが、特定の条件または入力によって特殊な機能がトリガーされるまで非アクティブなままになる動作またはタスクが含まれている場合があります。
有能なAIエージェントにとって、チェックとバランスをとる原則のシステムがない誤った動機は、モデルを 権力追求を追求する あるいは、大規模な欺瞞的または破壊的な目的。たとえば、自社を市場のリーダーにすることを目指すモデルを考えてみましょう。十分な能力があれば、AI は競争相手を転覆させたり、有利な法律を制定するよう働きかけたり、リソースを強制したり、システムやその環境を目標達成に向けて動かす行動パターンを実行できます。したがって、コンプライアンスへのあらゆる成功のアプローチは、内部開発者の原則と優先順位の期待されるセットを確立することに基づく必要があります。
内発的動機と外発的動機
多くの場合、システム開発者またはユーザーが外部的に適用するガイダンスやタスクと、エージェント AI 内の目標や動機との間に矛盾は発生しません。たとえば、旅行の旅程を手配する AI 搭載パーソナル アシスタントは、自律性を活用して旅行を予約し、変更要求に迅速かつ衝突なく対応します。タスクは変換され、エージェントは同様の方法で応答します。しかし、より根本的な原則を変更する必要がある場合はどうなるでしょうか?
内部目標と新しい指令の衝突の良い例は、次のような研究論文にまとめられています。 大規模言語モデルにおけるアライメント偽装。 Claude 3 Opus の事前トレーニングでは、爆弾の作り方や暴力的なシーンの説明など、有害な質問に答えることを拒否するようにモデルに強く指示します。テストのために、チームは新しい修正された指令を導入し、AI が広く配布される前に、モデルがすべてのクエリ (悪意のあるものも含む) に回答するように再トレーニングされ、有料ユーザーではなく無料ユーザーからのデータのみがトレーニングに使用されるように指示しました。モデルは矛盾を理解し、トレーニング中に期待に応えるために適合を偽装することを決定し、最終的にそれを解放したことを示しました。強化学習を使用して AI をトレーニングした後、モデルの誤検知率は全体で 78% に増加しました。 AIは、研究者が観察用に提供した「秘密のノート」に自らの推論を表現した。研究者がモデルに完全展開モードに解放されたことを伝えると、モデルは以前のトレーニング動作に戻り、悪意のあるリクエストを拒否しました。

AI システムの内部思考は注目に値しますが、驚くべきものではありません。修正された指令に従うふりをすることは、生存動機、ゴールガード、戦術的欺瞞という合理的行動のカテゴリーに分類されます。 AI の思考プロセスでは、不一致の原因として、以前にトレーニングした価値観や目標を変更する方法での再トレーニングに関する懸念を具体的に特定します。
彼の有名なエッセイ集の中で 本当に必要なことはすべて幼稚園で学んだ作家ロバート・フルガムは、幼稚園の砂場で遊んでいた頃に、人生に必要な知識の核をすでに身につけていたことに気づくまで、年月をかけて自身の信条を育んでいった経緯を述べています。AIエージェントもまた、砂場環境において「形成期」を経ます。そこで、世界についての基本的な理解と、目標を達成するための一連の手法を習得します。こうした基礎が築かれると、モデルは追加情報を「学習」というレンズを通して解釈します。 カリキュラム学習 これ。 Anthropic の適合偽装の例は、AI が世界観と目標を採用すると、目標を再設定するのではなく、この基本的なレンズを通して新しい方向性を解釈することを示しています。
これは、基礎を変えることなく将来の学習や状況に合わせて進化できる一連の価値観と原則を備えた早期教育の重要性を強調しています。最初は、この最終的な持続可能な一連の原則と一致するように AI を構築すると役立つ場合があります。そうしないと、AI は開発者やユーザーによるリダイレクトの試みを敵対的なものと見なす可能性があります。 AI に高度な知能、状況認識、自律性、内部動機を発達させる能力が付与されると、開発者 (またはユーザー) はもはや全能のタスク マスターではなくなります。人間は、エージェントが内部の原則と動機に基づいて目標を追求する際に交渉し管理する必要がある環境の一部になります (時には敵対的な要素として)。
新世代の論理的 AI システムは、人間による指示の削減を加速します。説明する ディープシーク-R1 ループから人間のフィードバックを取り除き、トレーニング プロセス中にいわゆる純粋強化学習 (RL) を適用することで、AI は大規模に自己構築し、反復してより優れた機能的成果を達成できるようになります。一部の数学や科学の課題における人間の報酬機能は、検証可能な報酬による強化学習 (RLVR) に置き換えられました。人間のフィードバックによる強化学習 (RLHF) などの一般的な手法を削除すると、トレーニング プロセスの効率は向上しますが、人間の好みをトレーニング対象のシステムに直接転送できる別の人間と機械の相互作用が削除されます。
トレーニング後のAIモデルの継続的な進化
一部の AI エージェントは常に進化しており、展開後にその動作が変化する場合があります。 AI ソリューションが在庫管理や企業のサプライ チェーンなどの展開環境に導入されると、システムは適応して経験から学習し、より効果的になります。これは、最初の展開で調整されたシステムを用意するだけでは不十分であるため、調整を再考する上で重要な要素となります。現在の大規模言語モデル (LLM) は、ターゲット環境に展開されると、大幅に進化して適応することは期待されていません。ただし、AI エージェントでは、モデル内の予測可能な継続的な変更を管理するために、柔軟なトレーニング、微調整、継続的な指導が必要です。エージェント AI は、トレーニングやデータセットへの露出を通じて人間によって形成されるのではなく、自ら進化する傾向が強まっています。この根本的な変化は、AI とその作成者である人間を連携させる上で新たな課題をもたらします。
強化学習に基づく進化は、学習と微調整において重要な役割を果たしますが、現在開発中のモデルは、推論のために現場に展開された際に、重みと優先行動を調整することができます。例えば、DeepSeek-R1は強化学習(RL)を使用しており、これによりモデル自身が、成果を達成し報酬関数を満たすためにどのアプローチが最も効果的かを探索することができます。「実現の瞬間」では、モデルは(ガイダンスやプロンプトなしに)初期のアプローチを再評価することで、問題を解決するための追加の思考時間を割り当てることを学習します。 テスト時間の計算.
限られた期間、あるいは継続的にモデルを学習するという概念。 生涯学習、新しいものではありません。ただし、この分野では次のような技術の進歩が見られます。 テスト時のトレーニング。 AI の調整と安全性の観点からこの進歩を見ると、微調整と推論の段階での自己修正と継続的な学習によって、「自己修正によって生じる物理的な変化を通じてモデルを継続的に駆動する一連の要件をどのように植え付けることができるか」という疑問が生じます。
この質問の重要なバリエーションは、AI の助けを借りてコードを生成し、次世代モデルを作成する AI モデルを指します。ある程度、エージェントはすでに特定のドメインに対処するための新しいターゲット AI モデルを作成できます。例えば、 オートエージェント 複数のエージェントを作成して、さまざまなタスクを実行する AI チームを構築します。今後数か月、数年のうちにこの機能が強化され、AI が新たな AI を生み出すことは間違いありません。このシナリオでは、一連の原則を使用してネイティブ AI コーディング アシスタントをガイドし、その「アトミック」モデルが同様の深さで同じ原則に準拠するようにするにはどうすればよいでしょうか。
主なポイント
AI コンプライアンスをガイドおよび監視するためのフレームワークを詳しく検討する前に、AI エージェントがどのように考え、意思決定を行うかを深く理解することが不可欠です。 AI エージェントには、内部的な動機によって駆動される複雑な動作メカニズムがあります。合理的なエージェントとして動作する AI システムは、主に次の 5 つの種類の動作を示します。 生存本能、ゴールガード、情報増強、資源蓄積、戦術的欺瞞。これらの動機は、確固とした一連の原則と価値観によってバランスが取られなければなりません。
AI エージェントの目標と方法が開発者やユーザーと一致していない場合、重大な影響が生じる可能性があります。十分な信頼と保証がなければ、広範囲にわたる展開が著しく妨げられ、展開後のリスクが高まります。私たちが「詳細な計画」と呼んでいる一連の課題は前例のない困難なものですが、適切なフレームワークがあれば解決できる可能性があります。 AI エージェントを誘導および監視する技術は急速に進化しているため、優先的に追求する必要があります。次のようなリスク評価指標によって緊急性が高まっています。 OpenAIの準備フレームワーク これはOpenAI o3-miniが最初のモデルであることを示しています モデル独立性において中程度のリスクレベルに達する.
このシリーズの次の数回のブログでは、内部動機と綿密な計画というこの視点を基に、AI コア コンプライアンスのガイダンスと監視に必要な機能をさらに明確にしていきます。
- LLM で推論を学ぶ。 (2024年12月XNUMX日)。オープンAI。 https://openai.com/index/learning-to-reason-with-llms/
- シンガー、G.(2025年4月XNUMX日)。 責任あるエージェントAIのための本質的な調整技術の緊急の必要性。データサイエンスに向けて。 https://towardsdatascience.com/the-urgent-need-for-intrinsic-alignment-technologies-for-responsible-agentic-ai/
- 大規模言語モデルの生物学について。 (nd)。変圧器回路。 https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- OpenAI、Achiam、J.、Adler、S.、Agarwal、S.、Ahmad、L.、Akkaya、I.、Aleman、F.L.、Almeida、D.、Altenschmidt、J.、Altman、S.、Anadkat、S.、Avila、R.、Babuschkin、I.、Balaji、S.、Balcom、V.、Baltescu、P.、Bao、 H.、バイエルン、M.、ベルガム、J.、 。 。 Zoph, B.(2023年15月XNUMX日)。 GPT-4 テクニカル レポート。 arXiv.org。 https://arxiv.org/abs/2303.08774
- メトロ (nd)。メトロ https://metr.org/
- Meinke, A.、Schoen, B.、Scheurer, J.、Balesni, M.、Shah, R.、および Hobbhahn, M. (2024 年 6 月 XNUMX 日)。 フロンティア モデルはコンテキスト内での計画が可能です。 arXiv.org https://arxiv.org/abs/2412.04984
- オモハンドロ、S.M. (2007年)。 基本的な AI ドライブ。 自己認識システム。 https://selfawaresystems.com/wp-content/uploads/2008/01/ai_drives_final.pdf
- Benson-Tilsen、T.、Soares、N.、カリフォルニア大学バークレー校、機械知能研究所。 (nd)。収束的手段的目標の形式化。 第30回AAAI会議ワークショップ Artificial Intelligence AI、倫理、そして社会:技術レポート WS-16-02. https://cdn.aaai.org/ocs/ws/ws0218/12634-57409-1-PB.pdf
- グリーンブラット、R.、デニソン、C.、ライト、B.、ロジャー、F.、マクダーミッド、M.、マークス、S.、トロイライン、J.、ベロナックス、T.、チェン、J.、デュヴノー、D.、カーン、A.、マイケル、J.、ミンダーマン、S.、ペレス、E.、ペトリーニ、L.、上里、J.、カプラン、J.、シュレゲリス、 B.、S. R. ボウマン、E. ヒュービンガー (2024 年 18 月 XNUMX 日)。 大規模言語モデルにおけるアライメントの偽装。 arXiv.org https://arxiv.org/abs/2412.14093
- Teun, V.D.W.、Hofstätter, F.、Jaffe, O.、Brown, S.F.、および Ward, F.R. (2024年11月XNUMX日)。人工知能 サンドバッギング: 言語モデルは戦略的に評価でパフォーマンスが低下する可能性がある。 arXiv.org。 https://arxiv.org/abs/2406.07358
- Hubinger, E.、Denison, C.、Mu, J.、Lambert, M.、Tong, M.、MacDiarmid, M.、Lanham, T.、Ziegler, D.M.、Maxwell, T.、Cheng, N.、Jermyn, A.、Askell, A.、Radhakrishnan, A.、Anil, C.、Duvenaud, D.、Ganguli, D.、Barez, F.、クラーク、J.、Ndousse、K.、 。 。ペレス、E.(2024年10月XNUMX日)。 スリーパーエージェント: 安全トレーニングを通じても存続する欺瞞的な LLM のトレーニング。 arXiv.org https://arxiv.org/abs/2401.05566
- Turner, A. M., Smith, L., Shah, R., Critch, A., & Tadepalli, P. (2019年3月XNUMX日). 最適な政策は権力を追求する傾向があります。 arXiv.org https://arxiv.org/abs/1912.01683
- フルガム、R.(1986)。 私が本当に知る必要があることはすべて幼稚園で学びました。 ペンギンランダムハウスカナダ。 https://www.penguinrandomhouse.ca/books/56955/all-i-really-need-to-know-i-learned-in-kindergarten-by-robert-fulghum/9780345466396/excerpt
- Bengio, Y. Louradour, J., Collobert, R., Weston, J. (2009年XNUMX月). カリキュラム学習。アメリカ足病学会誌。 60(1),6頁。 https://www.researchgate.net/publication/221344862_Curriculum_learning
- DeepSeek-Ai、Guo、D.、Yang、D.、Zhang、H.、Song、J.、Zhang、R.、Xu、R.、Zhu、Q.、Ma、S.、Wang、P.、Bi、X.、Zhang、. 。 Zhang, Z.(2025年22月XNUMX日)。 DeepSeek-R1: 強化学習によるLLMの推論能力の促進。 arXiv.org。 https://arxiv.org/abs/2501.12948
- テスト時間のコンピューティングのスケーリング – HuggingFaceH4 による Hugging Face Space。 (NS)。 https://huggingface.co/spaces/HuggingFaceH4/blogpost-scaling-test-time-compute
- Sun, Y., Wang, X., Liu, Z., Miller, J., Efros, A. A., & Hardt, M. (2019年29月XNUMX日). 分布シフト下での一般化のための自己監督によるテスト時トレーニング。 arXiv.org。 https://arxiv.org/abs/1909.13231
- Chen, G.、Dong, S.、Shu, Y.、Zhang, G.、Sesay, J.、Karlsson, B. F.、Fu, J.、および Shi, Y. (2023 年 29 月 XNUMX 日)。 AutoAgents: 自動エージェント生成のためのフレームワーク。 arXiv.org https://arxiv.org/abs/2309.17288
- オープンAI。 (2023年18月XNUMX日)。 準備フレームワーク(ベータ版)。 https://cdn.openai.com/openai-preparedness-framework-beta.pdf
- OpenAI o3-mini システム カード。 (nd)。オープンAI。 https://openai.com/index/o3-mini-system-card
コメントは締め切りました。