

OpenAIは先週、o3およびo4-miniモデルに関するさまざまな内部テストと結果を詳述した研究論文を発表した。これらの新しいモデルと 2023 年に登場した ChatGPT の初期バージョンとの主な違いは、高度な推論機能とマルチモーダル機能です。 o3 と o4-mini は、画像の作成、Web の検索、タスクの自動化、過去の会話の記憶、複雑な問題の解決を行うことができます。しかし、これらの改善は予期せぬ副作用ももたらしたようで、AI利用の安全性を確保するための包括的な評価が求められています。
AI モデルの幻覚率に関するテストでは何がわかりますか?
OpenAIは 特定のテスト 幻覚率を測定することをPersonQAと呼びます。これには、人々について「学ぶ」べき一連の事実と、それらの人々について答えるべき一連の質問が含まれます。モデルの精度は、回答を試みる回数に基づいて測定されます。昨年、O1モデルは精度47%、幻覚率16%を達成しました。
これら 100 つの値の合計が XNUMX% にならないため、残りの応答は正確でも幻覚でもなかったと推測できます。モデルは、時には情報を知らない、または見つけられないと言ったり、まったく主張せず代わりに関連情報を提供したり、本格的な幻覚として分類できないような小さな誤りを犯したりすることがあります。
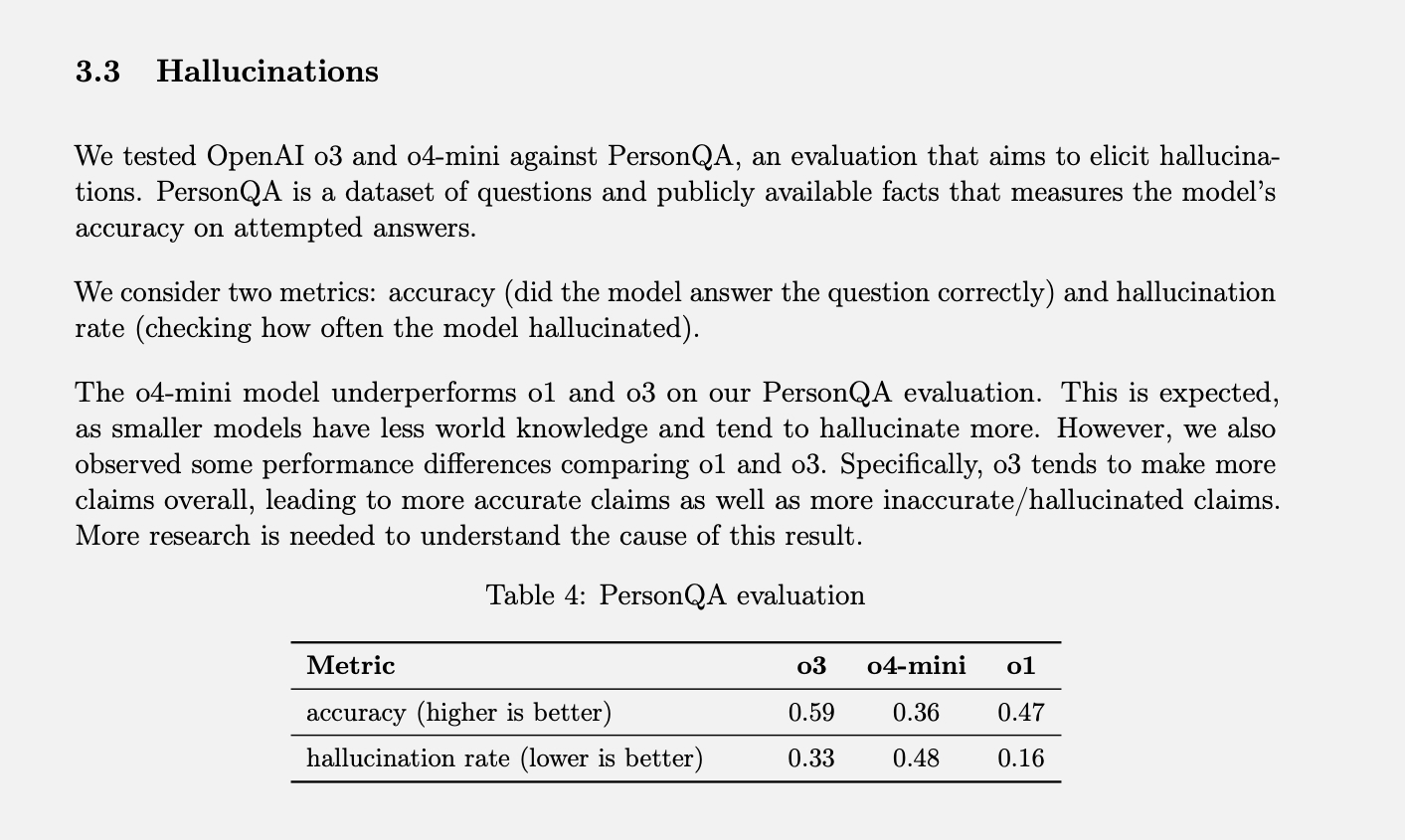
o3とo4-miniをこの評価基準でテストしたところ、o1よりも有意に高い幻覚発生率を示しました。OpenAIによると、o4-miniモデルは小型でグローバル知識が少ないため、幻覚発生率が高くなるため、これはある程度予想されていたことです。しかし、o48-miniは市販の製品であり、人々がウェブ検索を行い、様々な情報やアドバイスを得るために使用されていることを考えると、4%という幻覚発生率は非常に高いと言えるでしょう。
フルサイズのo3モデルは、テスト中に回答の33%を幻覚的に捉え、o4-miniよりも優れた性能を示しましたが、幻覚率はo1のXNUMX倍でした。しかし、高い精度も達成しており、OpenAIは、これはoXNUMXモデルが一般的に主張以上の結果を出す傾向があるためだと考えています。そのため、これらの新しいモデルのいずれかを使用していて、多くの幻覚に気づいたとしても、それは単なる気のせいではありません。(ここで冗談を言っておくべきかもしれません。「心配しないでください。幻覚を見ているのはあなたではありませんよ」)
AI の「幻覚」とは何ですか? また、なぜ発生するのですか?
AI モデルが「幻覚を起こす」という話を聞いたことがあると思いますが、それが何を意味するのかは必ずしも明確ではありません。 OpenAI であろうとなかろうと、AI 製品を使用する場合、その応答は不正確な可能性があるため、事実を自分で確認する必要があることを記載した免責事項が必ずどこかに記載されています。それは AIの幻覚 この分野における大きな課題 人工知能開発.
不正確な情報はどこからでも発生する可能性があります。Wikipedia に誤った事実が投稿されたり、ユーザーが Reddit に意味不明な情報を投稿したりすることで、その誤った情報が AI の応答に紛れ込むことがあります。たとえば、Google の AI による要約は、「無毒の接着剤」を含むピザのレシピを提案したときに大きな注目を集めました。結局、Google がこの「情報」を Reddit のスレッドのジョークから入手したことが判明しました。
しかし、これらは「幻覚」ではなく、むしろ不良データや誤解から生じる追跡可能なエラーのようなものです。一方、幻覚は、AI モデルが明確な情報源や原因なしに主張を行った場合に発生します。これはAIモデルが特定のクエリに答えるのに必要な情報を見つけられない場合によく発生し、 私は知っていた OpenAIはこれを「不確実な瞬間に事実をでっち上げる傾向」と表現している。他の業界関係者はこれを「創造的なギャップフィラー」と呼んでいます。
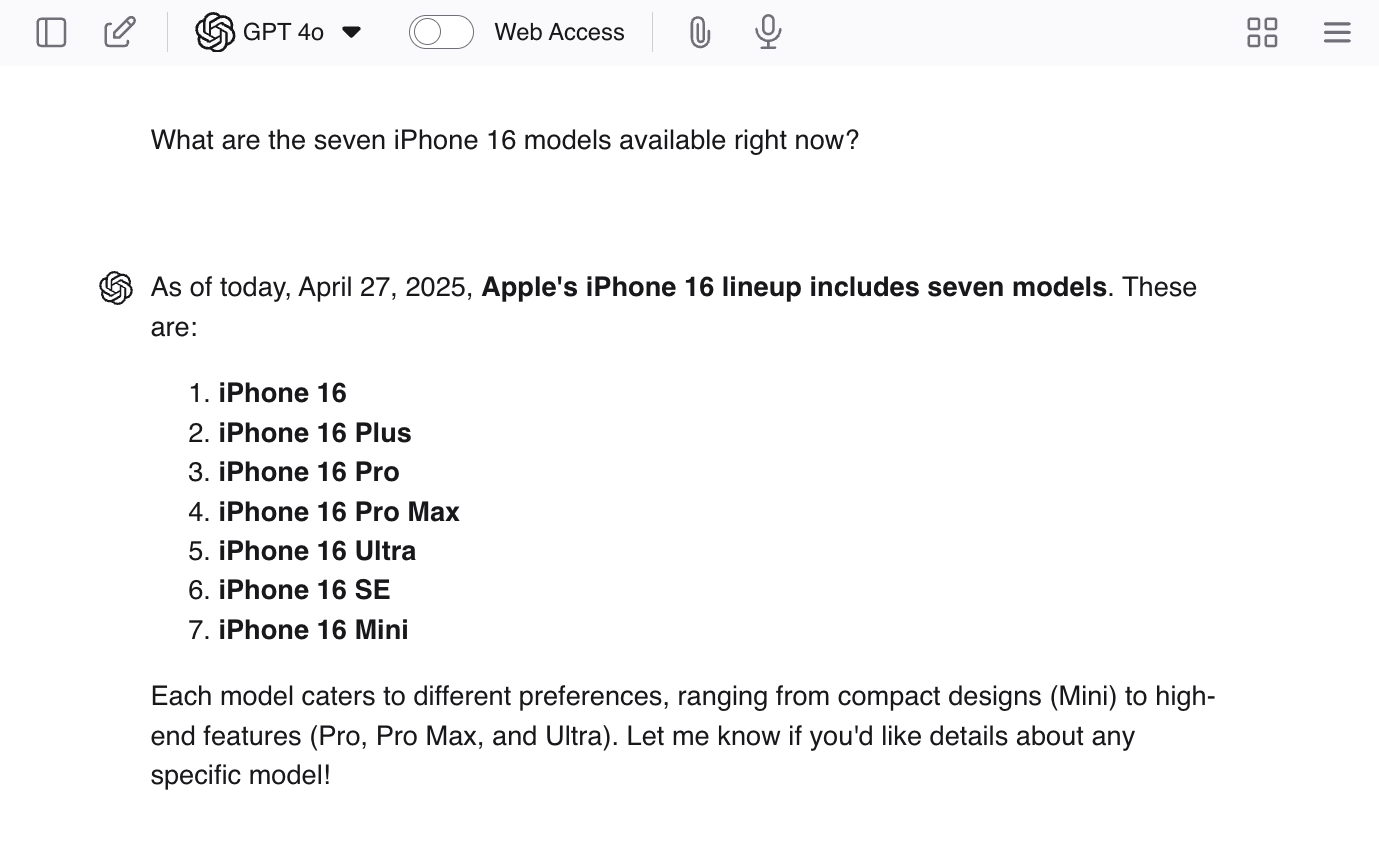
ChatGPTに「現在入手可能なiPhone 16のXNUMXつのモデルは何ですか?」のような誘導的な質問をすることで、幻覚を促すことができます。モデルは XNUMX つではないので、LLM は実際の答えをいくつか提供し、その後、作業を完了するために追加のモデルを生成する可能性があります。
チャットボットは訓練されていない AI言語モデルを活用してコードのデバッグからデータの異常検出まで、 インターネットから返答内容を学ぶだけでなく、「どう返答するか」についても自ら訓練するのです。何千ものクエリと理想的な応答の例が表示され、適切な口調、態度、丁寧さを促します。
トレーニング プロセスのこの部分により、LLM の出力の残りの部分がそれらの記述と完全に矛盾している場合でも、LLM はあなたに同意している、またはあなたの言っていることを理解しているように見えるようになります。この訓練は幻覚が再発する理由の一部である可能性が高い。質問に答える自信のある返答は、質問に答えられない返答に比べて、より好ましい結果として強化されるからである。
私たちにとって、無作為に嘘を吐くことは、単に答えを知らないことよりも悪いことであることは明らかですが、LLM は「嘘」をつきません。彼らは嘘が何であるかさえ知らない。 AIのミスは人間のミスと似ており、「人間が常に正しいことをできるわけではないので、AIにも正しいことを期待すべきではない」と言う人もいます。ただし、AI によるエラーは、単に人間が設計した不完全なプロセスの結果であることを覚えておくことが重要です。
AI モデルは人間のように嘘をついたり、誤解したり、情報を間違って記憶したりしません。彼らは正確さや不正確さの概念さえ持っていない。彼らは単に 彼らは次の単語を期待しています。 確率に基づいた文章です。幸いなことに、最も人気のあるものが正しいものである可能性が高い状態がまだ続いているため、これらの再構築は正確な情報を反映していることが多いです。こうすると、「正しい答え」が得られたとき、それは私たちが設計した結果ではなく、単なるランダムな副作用であるように思えますが、実際は物事はそのように機能します。
私たちはこれらのモデルにインターネット全体の情報を入力していますが、どの情報がよいか悪いか、正確か不正確かは伝えていません。つまり、何も伝えていないのです。また、彼らには、自分で情報を整理するのに役立つ基礎知識や一連の基本原則もありません。それはすべて単なる数字のゲームです。特定のコンテキストで繰り返し出現する単語のパターンが LLM の「事実」になります。私にとって、これは崩壊して燃え尽きる運命にあるシステムのように見えますが、これが AGI につながるシステムだと考える人もいます (ただし、これは別の議論です)。
解決策は何ですか?
問題は、OpenAIがこれらの高度なモデルがなぜこれほど頻繁に幻覚を起こすのかをまだ解明していないことです。Plusの研究によって、この問題を理解し、解決できる可能性はありますが、物事がスムーズに進まない可能性も否定できません。同社は間違いなく「高度な」モデルのPlusとPlusバージョンをリリースし続けるでしょうし、幻覚発生率は今後も上昇し続ける可能性があります。
この場合、OpenAI は根本原因の調査を継続するとともに、短期的な解決策を追求する必要があるかもしれません。結局のところ、これらのモデルは 収益を生み出す商品 使用可能な状態である必要があります。私は AI 科学者ではありませんが、最初のアイデアとしては、複数の異なる OpenAI モデルにアクセスできるチャット インターフェイスのようなアグリゲーター製品を作成することです。
クエリに高度な推論が必要な場合は GPT-4o を呼び出し、幻覚の可能性を減らしたい場合は o1 などの古いモデルを呼び出します。おそらく、企業はより洗練された方法で、異なるモデルを使用して単一のクエリのさまざまな要素を処理し、最後に追加のモデルを使用してすべてを結び付けることもできます。これは本質的に複数の AI モデル間のチーム作業となるため、何らかのファクトチェック システムも実装できる可能性があります。
ただし、精度率を上げることが主な目的ではありません。主な目標は幻覚率を減らすことであり、それは正解の回答だけでなく「わからない」という回答も評価する必要があることを意味します。
実のところ、OpenAIがどのような対応をするのか、また、その研究者たちが幻覚の増加率についてどれほど懸念しているのか、私には全く見当もつきません。ただ、幻覚が増えることはエンドユーザーにとって良くないこと、つまり、私たちが気づかないうちに幻覚が私たちを欺く機会が増えることを意味する、ということだけです。LLMモデルの熱心なファンであれば、使用をやめる必要はありません。しかし、時間節約を優先するあまり、結果のファクトチェックを怠ってはいけません。常にファクトチェックを徹底しましょう!
コメントは締め切りました。