

登場以来 ジェミニ3 彼は初めてトップの座を維持することに成功した。 LMArena リーダーボードこのリストは、何千人もの実際のユーザーがモデルを比較した総合的なランキングです。 人工知能 幅広いタスクで互いに直接対決し、最適な回答を投票で決定します。しかし、最も厳しい推論基準を達成するとなると、新たなスターが現れます。それは既にGoogleを上回るパフォーマンスを発揮しており、しかも独自のモデルを学習させることなく達成しています。
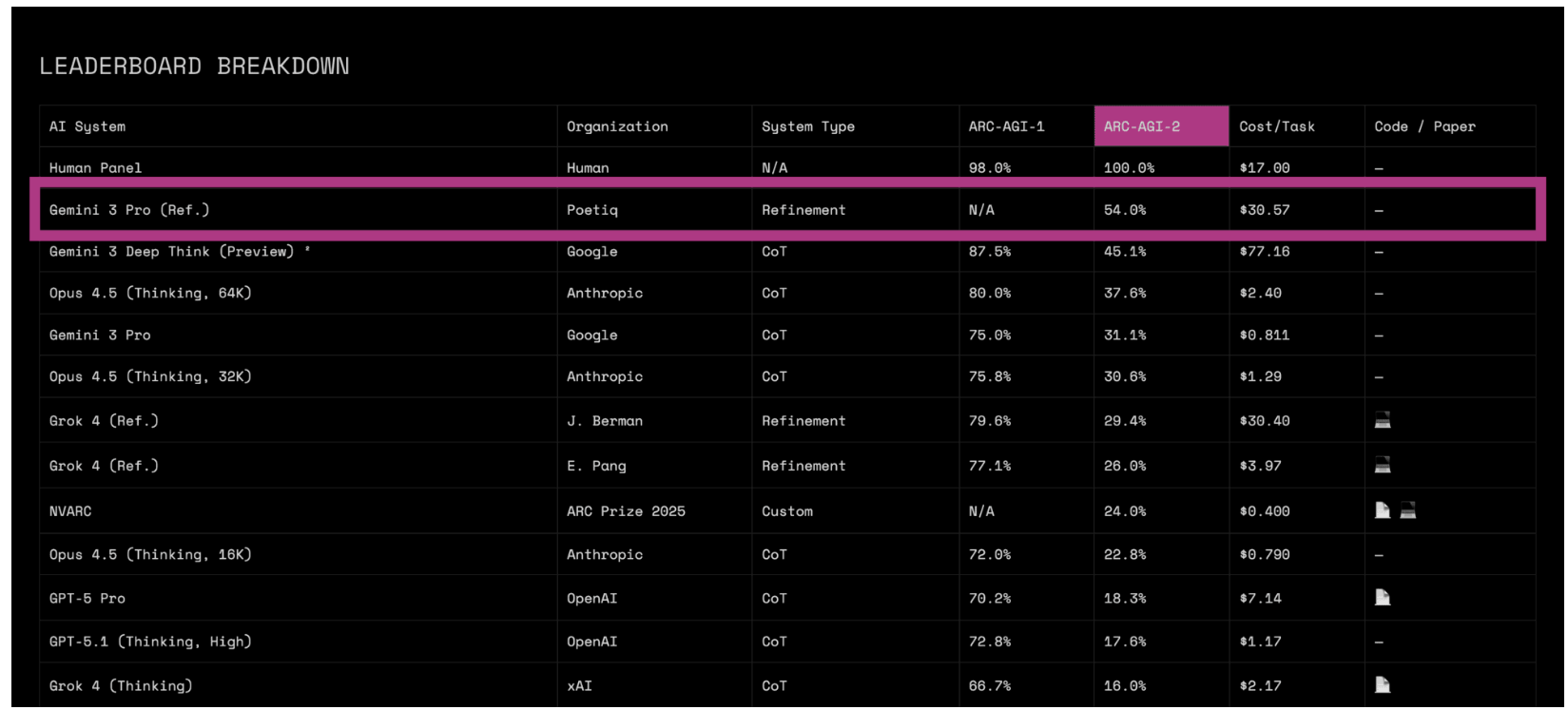
6人のスタートアップ企業Poetiqは、 ARC-AGI-2 セミスペシャルテストキットこれは、AI研究者フランソワ・ショレ氏が作成した極めて難解な推論チャレンジです。このスタートアップのシステムは54%の正解率を記録し、Googleが以前に発表したGemini 3 Deep Thinkの約45%というスコアを上回りました。

現状を鑑みると、わずか6ヶ月前までは、ほとんどのAIモデルがこのベンチマークで5%未満に留まっていました。50%を突破するには、研究者の間では何年もかかると広く考えられていました。
そして最も驚くべき点は、Poetiq の躍進は、新しいフロンティア モデルによって支えられたのではなく、既存のモデルをよりスマートに整理する方法によって支えられていたことです。
Poetiq はどのようにしてこの偉業を達成したのでしょうか?
Poetiqは、大規模なコンバーターをゼロから構築する代わりに、いわゆる「メタシステム」を開発しました。これは、接続されたあらゆるモデルの出力を監視、評価、改善するAIコントローラーです。ARC-AGI-2の研究では、チームはGemini 3 Proをベースモデルとして使用しました。
Poetiq 氏はこのシステムを、厳密に制御された最適化ループとして説明しています。 作成 > 批評 > 改善 > 確認。
これが特別な点です:
- 再トレーニングは不要です。 システムは数時間以内に新しいモデルに適応します。
- これは、大規模な既成の言語モデルに基づいて構築されています。 カスタム編集は利用できません
- 低価格または安価: Google の Deep Think はタスク 1 つあたり 77 ドルかかると報告されていますが、Poetiq のシステムは 30 ドル程度です。
- オープンソース: ソリューションは公開されており、検証可能です。
- 自己監査: システムは最終結果を返す前に独自の回答を評価します。
こんにちは ウェブサイト 同社のPoetiqチームによれば、このアプローチは、コンピューティングを強制的にスケールアップするのではなく、既存の大規模言語モデルの推論能力からPlusを抽出することによって機能する。
ARC-AGI-2 テストはなぜ重要ですか?

ほとんどの標準化されたテストはプログラミングや数学などの限られたスキルを測定しますが、ARC-AGI-2 はパターン認識、測定、抽象的推論、人間が幼少期に学ぶような一般化など、より深いスキルをテストするように設計されています。
これは意図的に難しく、現在の大規模言語モデル(LLM)にとって著しく不向きです。多くの洗練されたモデルでさえ、この方法では見事に失敗します。
そのため、半年で1桁台から54%へと急上昇したことは驚くべきことでした。これは、単にモデルの規模が大きくなっただけでなく、推論手法の進歩も示していると言えるでしょう。
しかし、Poetiq社の結果は、完全には公開されていない半非公開のテストグループにのみ適用されます。同社のウェブサイトには、この結果はベンチマーク機関によって検証済みであると記載されていますが、独立した第三者機関による再現はまだ行われていません。これは、この影響のベンチマークテストにとって重要な意味を持ちます。
ポエティック氏の研究は人工知能の成長傾向を浮き彫りにしており、次のブレークスルーはより大規模なモデルから生まれるものではないかもしれない。進歩には必ずしも数十億ドル規模のインフラや巨大な研究室が必要というわけではないのだ。
このようなシステムが標準的なパラメータを超えて、計画、プログラミング、研究、さらには現実世界の意思決定までをも包含することができれば、人工知能の開発方法を根本から変える可能性があります。企業は次世代のスーパーコンピュータを待つのではなく、既存のモデルをよりスマートに、より安価に、より一貫性のあるものにする複合知能の構築に注力するかもしれません。
結論
PoetiqはARC-AGI向けのオープンソースソリューションをリリースしました。これにより、研究者はARC-AGIの結果を検証、拡張、さらには異議申し立てを行うことができます。この標準には非公開のテストセットが含まれており、過去の事例から、相当数の人々が独立した評価を実施すれば、結果が変化する可能性があることが分かっています。
Poetiqの数値が妥当であれば、AI推論研究における転換点となる可能性があります。6人からなるチームが、モデルの組織化が、はるかに大規模なモデルの訓練に匹敵し、あるいは凌駕することさえ可能であることを示したと言えるかもしれません。Poetiqは、勝利するために巨大な研究室は必要ないことを証明したのです。
コメントは締め切りました。